
Главная
Рефераты по зарубежной литературе
Рефераты по логике
Рефераты по маркетингу
Рефераты по международному публичному праву
Рефераты по международному частному праву
Рефераты по международным отношениям
Рефераты по культуре и искусству
Рефераты по менеджменту
Рефераты по металлургии
Рефераты по муниципальному праву
Рефераты по налогообложению
Рефераты по оккультизму и уфологии
Рефераты по педагогике
Рефераты по политологии
Рефераты по праву
Биографии
Рефераты по предпринимательству
Рефераты по психологии
Рефераты по радиоэлектронике
Рефераты по риторике
Рефераты по социологии
Рефераты по статистике
Рефераты по страхованию
Рефераты по строительству
Рефераты по схемотехнике
Рефераты по таможенной системе
Сочинения по литературе и русскому языку
Рефераты по теории государства и права
Рефераты по теории организации
Рефераты по теплотехнике
Рефераты по технологии
Рефераты по товароведению
Рефераты по транспорту
Рефераты по трудовому праву
Рефераты по туризму
Рефераты по уголовному праву и процессу
Рефераты по управлению
Реферат: Статистический анализ числовых величин (непараметрическая статистика)
Реферат: Статистический анализ числовых величин (непараметрическая статистика)
РЕФЕРАТ
Статистический анализ числовых величин (непараметрическая статистика)
В учебных курсах по теории вероятностей и математической статистике рассматривают различные параметрические семейства распределений числовых случайных величин. А именно, изучают семейства нормальных распределений, логарифмически нормальных, экспоненциальных, гамма-распределений, распределений Вейбулла-Гнеденко и др. Все они зависят от одного, двух или трех параметров. Поэтому для полного описания распределения достаточно знать или оценить одно, два или три числа. Очень удобно. Поэтому широко развита параметрическая теория математической статистики, в которой предполагается, что распределения результатов наблюдений принадлежат тем или иным параметрическим семействам.
К сожалению, параметрические семейства существуют лишь в головах авторов учебников по теории вероятностей и математической статистике. В реальной жизни их нет. Поэтому эконометрика использует в основном непараметрические методы, в которых распределения результатов наблюдений могут иметь произвольный вид.
Сначала на примере нормального распределения подробнее обсудим невозможность практического использования параметрических семейств для описания распределений конкретных экономических данных. Затем разберем параметрические методы отбраковки резко выделяющихся наблюдений и продемонстрируем невозможность практического использования ряда методов параметрической статистики, ошибочность выводов, к которым они приводят. Затем разберем непараметрические методы доверительного оценивания основных характеристик числовых случайных величин - математического ожидания, медианы, дисперсии, среднего квадратического отклонения, коэффициента вариации. Завершат главу методы проверки однородности двух выборок, независимых или связанных.
Распределение результатов наблюдений
В эконометрических и экономико-математических моделях, применяемых, в частности, при изучении и оптимизации процессов маркетинга и менеджмента, управления предприятием и регионом, точности и стабильности технологических процессов, в задачах надежности, обеспечения безопасности, в том числе экологической, функционирования технических устройств и объектов, разработки организационных схем часто применяют понятия и результаты теории вероятностей и математической статистики. При этом зачастую используют те или иные параметрические семейства распределений вероятностей. Наиболее популярно нормальное распределение. Используют также логарифмически нормальное распределение, экспоненциальное распределение, гамма-распределение, распределение Вейбулла-Гнеденко и т.д.
Очевидно, всегда необходимо проверять соответствие моделей реальности. Возникают два вопроса. Отличаются ли реальные распределения от используемых в модели? Насколько это отличие влияет на выводы?
Ниже на примере нормального распределения и основанных на нем методов отбраковки резко отличающихся наблюдений (выбросов) показано, что реальные распределения практически всегда отличаются от включенных в классические параметрические семейства, а имеющиеся отклонения от заданных семейств делают неверными выводы, в рассматриваемом случае, об отбраковке, основанные на использовании этих семейств.
Есть ли основания априори предполагать нормальность результатов измерений?
Иногда утверждают, что в случае, когда погрешность измерения (или иная случайная величина) определяется в результате совокупного действия многих малых факторов, то в силу Центральной Предельной Теоремы (ЦПТ) теории вероятностей эта величина хорошо приближается (по распределению) нормальной случайной величиной. Такое утверждение справедливо, если малые факторы действуют аддитивно и независимо друг от друга. Если же они действуют мультипликативно, то в силу той же ЦПТ аппроксимировать надо логарифмически нормальным распределением. В прикладных задачах обосновать аддитивность, а не мультипликативность действия малых факторов обычно не удается. Если же зависимость имеет общий характер, не приводится к аддитивному или мультипликативному виду, а также нет оснований принимать модели, дающие экспоненциальное, Вейбулла-Гнеденко, гамма или иные распределения, то о распределении итоговой случайной величины практически ничего не известно, кроме внутриматематических свойств типа регулярности.
При обработке конкретных данных иногда считают, что погрешности измерений имеют нормальное распределение. На предположении нормальности построены классические модели регрессионного, дисперсионного, факторного анализов, метрологические модели, которые еще продолжают встречаться как в отечественной ноpмативно-технической документации, так и в международных стандартах. На то же предположение опираются модели расчетов максимально достигаемых уровней тех или иных характеристик, применяемые при проектировании систем обеспечения безопасности функционирования экономических структур, технических устройств и объектов. Однако теоретических оснований для такого предположения нет. Необходимо экспериментально изучать распределения погрешностей.
Что же показывают результаты экспериментов? Сводка, данная в монографии [1], позволяет утверждать, что в большинстве случаев распределение погрешностей измерений отличается от нормального. Так, в Машинно-электротехническом институте (г. Варна в Болгарии) было исследовано распределение погрешностей градуировки шкал аналоговых электроизмерительных приборов. Изучались приборы, изготовленные в Чехословакии, СССР и Болгарии. Закон распределения погрешностей оказался одним и тем же. Он имеет плотность
![]()
Были проанализированы данные о параметрах 219 фактических распределениях погрешностей, исследованных разными авторами, при измерении как электрических, так и не электрических величин самыми разнообразными (электрическими) приборами. В результате этого исследования оказалось, что 111 распределений, т.е. примерно 50% , принадлежат классу распределений с плотностью
![]()
где ![]() - параметр степени; b - параметр
сдвига;
- параметр степени; b - параметр
сдвига; ![]() -
параметр масштаба;
-
параметр масштаба; ![]() - гамма-функция от аргумента
- гамма-функция от аргумента ![]() ;
;
![]()
(см. [1, с. 56]); 63 распределения, т.е. 30%, имеют плотности с плоской вершиной и пологими длинными спадами и не могут быть описаны как нормальные или, например, экспоненциальные. Оставшиеся 45 распределений оказались двухмодальными.
В книге известного метролога проф. П. В. Hовицкого [2] приведены результаты исследования законов распределения различного рода погрешностей измерения. Он изучил распределения погрешностей электромеханических приборов на кернах, электронных приборов для измерения температур и усилий, цифровых приборов с ручным уpавновешиванием. Объем выборок экспериментальных данных для каждого экземпляра составлял 100-400 отсчетов. Оказалось, что 46 из 47 распределений значимо отличались от нормального. Исследована форма распределения погрешностей у 25 экземпляров цифровых вольтметров Щ-1411 в 10 точках диапазона. Результаты аналогичны. Дальнейшие сведения содержатся в монографии [1].
В лаборатории прикладной математики Тартуского государственного университета проанализировано 2500 выбоpок из архива реальных статистических данных. В 92% гипотезу нормальности пришлось отвергнуть.
Приведенные описания экспеpиментальных данных показывают, что погрешности измерений в большинстве случаев имеют распределения, отличные от нормальных. Это означает, в частности, что большинство применений критерия Стьюдента, классического регрессионного анализа и других статистических методов, основанных на нормальной теории, строго говоря, не является обоснованным, поскольку неверна лежащая в их основе аксиома нормальности распределений соответствующих случайных величин.
Очевидно, для оправдания или обоснованного изменения существующей практики анализа статистических данных требуется изучить свойства процедур анализа данных при "незаконном" применении. Изучение процедур отбраковки показало, что они крайне неустойчивы к отклонениям от нормальности, а потому применять их для обработки реальных данных нецелесообразно (см. ниже); поэтому нельзя утверждать, что произвольно взятая процедура устойчива к отклонениям от нормальности.
Иногда предлагают перед применением, например, критерия Стьюдента однородности двух выбоpок проверять нормальность. Хотя для этого имеется много критериев, но проверка нормальности - более сложная и трудоемкая статистическая процедура, чем проверка однородности (как с помощью статистик типа Стьюдента, так и с помощью непараметрических критериев). Для достаточно надежного установления нормальности требуется весьма большое число наблюдений. Так, чтобы гарантировать, что функция распределения результатов наблюдений отличается от некоторой нормальной не более, чем на 0,01 (при любом значении аргумента), требуется порядка 2500 наблюдений. В большинстве экономических, технических, медико-биологических и других прикладных исследований число наблюдений существенно меньше. Особенно это справедливо для данных, используемых при изучении проблем, связанных с обеспечением безопасности функционирования экономических структур и технических объектов.
Иногда пытаются использовать ЦПТ для приближения
распределения погрешности к нормальному, включая в технологическую схему
измерительного прибора специальные сумматоры. Оценим полезность этой меры.
Пусть Z1 , Z2 ,…, Zk - независимые одинаково
распределенные случайные величины с функцией распределения H = H(x) такие, что ![]() Рассмотрим
Рассмотрим
![]()
Показателем обеспечиваемой сумматором близости к нормальности является
![]()
Тогда
![]()
Правое неравенство в последнем соотношении вытекает из
оценок константы в неравенстве Берри-Эссеена, полученном в книге [3, с.172], а
левое - из примера в монографии [4, с.140-141]. Для нормального закона ![]() =1,6, для
равномерного
=1,6, для
равномерного ![]() = 1,3, для двухточечного
= 1,3, для двухточечного ![]() =1 (это -
нижняя граница для
=1 (это -
нижняя граница для ![]() ). Следовательно, для обеспечения
расстояния (в метрике Колмогорова) до нормального распределения не более 0,01
для "неудачных" распределений необходимо не менее k0 слагаемых,
где
). Следовательно, для обеспечения
расстояния (в метрике Колмогорова) до нормального распределения не более 0,01
для "неудачных" распределений необходимо не менее k0 слагаемых,
где
![]()
В обычно используемых сумматорах слагаемых значительно меньше. Сужая класс возможных распределений H, можно получить, как показано в монографии [5], более быструю сходимость, но теория здесь еще не смыкается с практикой. Кроме того, не ясно, обеспечивает ли близость распределения к нормальному (в определенной метрике) также и близость распределения статистики, построенной по случайным величинам с этим распределением, к распределению статистики, соответствующей нормальным результатам наблюдений. Видимо, для каждой конкретной статистики необходимы специальные теоретические исследования, Именно к такому выводу приходит автор монографии [5]. В задачах отбраковки выбросов ответ: "Не обеспечивает" (см. ниже).
Отметим, что результат любого реального измерения записывается с помощью конечного числа десятичных знаков, обычно небольшого (2-5), так что любые реальные данные целесообразно моделировать лишь с помощью дискретных случайных величин, принимающих конечное число значений. Нормальное распределение - лишь аппроксимация реального распределения. Так, например, данные конкретного исследования, приведенные в работе [6], принимают значения от 1,0 до 2,2, т.е. всего 13 возможных значений. Из принципа Дирихле следует, что в какой-то точке построенная по данным работы [6] функция распределения отличается от ближайшей функции нормального распределения не менее чем на 1/26, т.е. на 0,04. Кроме того, очевидно, что для нормального распределения случайной величины вероятность попасть в дискретное множество десятичных чисел с заданным числом знаков после запятой равна 0.
Из сказанного выше следует, что результаты измерений и вообще статистические данные имеют свойства, приводящие к тому, что моделировать их следует случайными величинами с распределениями, более или менее отличными от нормальных. В большинстве случаев распределения существенно отличаются от нормальных, в других нормальные распределения могут, видимо, рассматриваться как некоторая аппроксимация, но никогда нет полного совпадения. Отсюда вытекает как необходимость изучения свойств классических статистических процедур в неклассических вероятностных моделях (подобно тому, как это сделано ниже для критерия Стьюдента), так и необходимость разработки устойчивых (учитывающих наличие отклонений от нормальности) и непараметрических, в том числе свободных от распределения процедур, их широкого внедрения в практику статистической обработки данных.
Опущенные здесь рассмотрения для других параметрических семейств приводят к аналогичным выводам. Итог можно сформулировать так. Распределения реальных данных практически никогда не входят в какое-либо конкретное параметрическое семейство. Реальные распределения всегда отличаются от тех, что включены в параметрические семейства. Отличия могут быть большие или маленькие, но они всегда есть. Попробуем понять, насколько важны эти различия для проведения эконометрического анализа.
Неустойчивость параметрических методов отбраковки резко выделяющихся результатов наблюдений
При обработки реальных экономических данных, полученных в процессе наблюдений, измерений, расчетов, иногда один или несколько результатов наблюдений резко выделяются, т.е. далеко отстоят от основной массы данных. Такие резко выделяющиеся результаты наблюдений часто считают содержащими грубые погрешности, соответственно называют промахами или выбросами. В рассматриваемых случаях возникает естественная мысль о том, что подобные наблюдения не относятся к изучаемой совокупности, поскольку содержат грубую погрешность, а получены в результате ошибки, промаха. В метрологии об этом явлении говорят так: "Грубые погрешности и промахи возникают из-за ошибок или неправильных действий оператора (его психо-физиологического состояния, неверного отсчета, ошибок в записях или вычислениях, неправильного включения приборов и т.п.), а также при кратковременных резких изменений проведения измерений (вибрации, поступления холодного воздуха, толчка прибора оператором и т.п.). Если грубые погрешности и промахи обнаруживают в процессе измерений, то результаты, содержащие их, отбрасывают. Однако чаще всего их выявляют только при окончательной обработке результатов измерений с помощью специальных критериев оценки грубых погрешностей" [7, с.46-47].
Есть два подхода к обработке данных, которые могут быть искажены грубыми погрешностями и промахами:
1) отбраковка резко выделяющихся результатов наблюдений, т.е. обнаружение наблюдений, искаженных грубыми погрешностями и промахами, и исключение их из дальнейшей статистической обработки;
2) применение устойчивых (робастных) методов обработки данных, На результаты работы которых мало влияет наличие небольшого числа грубо искаженных наблюдений (см. ниже соответствующую главу).
В настоящем пункте обсуждаются методы отбраковки.
Наиболее изучена ситуация, когда результаты наблюдений - числа x1., x2.,…, xn., резко выделяется один результат наблюдения, для определенности, максимальный xmax .
Простейшая вероятностно-статистическая модель такова
[8]. При нулевой гипотезе H0 результаты наблюдения x1., x2.,…,
xn рассматриваются как реализация независимых одинаково
распределенных случайных величин числа X1., X2.,…, Xn.
с функцией распределения F(x). При альтернативной гипотезе H1
случайные величины X1., X2.,…, Xn. также
независимы, X1., X2.,…, Xn-1 имеют
распределение F(x), а Xn - распределение G(x), оно "существенно
сдвинуто вправо" относительно F(x), например, G(x)=F(x - A), где A
достаточно велико. Если альтернативная гипотеза справедлива, то при ![]() вероятность
равенства
вероятность
равенства
![]()
стремится к 1, поэтому естественно применять решающее правило следующего вида:
если xmax.> d, то принять H1.,
если xmax.< d, то принять H0 , (1)
где d - параметр решающего правила, который следует определять из вероятностно-статистических соображений.
При справедливости нулевой гипотезы
![]()
Статистический критерий проверки гипотезы H0 ,
основанный на решающем правиле вида (1), имеет уровень значимости ![]() , если
, если
![]()
т.е.
![]() (2)
(2)
Из соотношения (2) определяют граничное значение d=d(![]() , n) в решающем
правиле (1).
, n) в решающем
правиле (1).
При больших n и малых ![]()
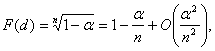 (3)
(3)
поэтому в качестве хорошего приближения к d(![]() , n)
рассматривают (1-
, n)
рассматривают (1-![]() /n) - квантиль распределения F(x).
/n) - квантиль распределения F(x).
Пусть правило отбраковки задано в соответствии с выражениями (1) и (2) с некоторой функцией распределения F, однако выборка берется из функции распределения G, мало отличающейся от F в смысле расстояния Колмогорова
![]() (4)
(4)
С помощью соотношения (3) получаем, что величина ![]() = G(d) для d из
уравнения (2) находится между
= G(d) для d из
уравнения (2) находится между ![]() и
и ![]() . Уровень значимости критерия,
построенного для F, при применении к наблюдениям из G есть 1-
. Уровень значимости критерия,
построенного для F, при применении к наблюдениям из G есть 1-![]() и может принимать любые
значения в отрезке [1-
и может принимать любые
значения в отрезке [1-![]() ; 1-
; 1-![]() ]. В частности, при
]. В частности, при ![]() = 0,01,
= 0,01, ![]() =0,05, n = 5 возможные
значения уровня значимости заполняют отрезок [0; 0,1], т.е. уровень значимости
может быть в 2 раза выше номинального, а если n возрастает до 30, то
максимальный уровень значимости есть 0,297, т.е. почти в 6 раз выше
номинального. При дальнейшем росте n верхняя граница для уровня значимости, как
нетрудно видеть, приближается к 1.
=0,05, n = 5 возможные
значения уровня значимости заполняют отрезок [0; 0,1], т.е. уровень значимости
может быть в 2 раза выше номинального, а если n возрастает до 30, то
максимальный уровень значимости есть 0,297, т.е. почти в 6 раз выше
номинального. При дальнейшем росте n верхняя граница для уровня значимости, как
нетрудно видеть, приближается к 1.
Рассмотрим и другой вопрос - насколько правило
отбраковки с уровнем значимости ![]() для G может отличаться от
такового для F при справедливости неравенства (4). С использованием соотношения
(3) заключаем, что из
для G может отличаться от
такового для F при справедливости неравенства (4). С использованием соотношения
(3) заключаем, что из
![]() (5)
(5)
следует, что ![]() где
где ![]() и
и ![]() выписаны выше. Решение уравнения
(5) может принимать любое значение в отрезке [
выписаны выше. Решение уравнения
(5) может принимать любое значение в отрезке [![]() ]. В частности, при
]. В частности, при ![]() =0,05 и n = 5 для
стандартного нормального распределения F имеем d(
=0,05 и n = 5 для
стандартного нормального распределения F имеем d(![]() , n) = 2,319, при
, n) = 2,319, при ![]() =0,01 решение уравнения
(5) может принимать любое значение в отрезке [2,054; +
=0,01 решение уравнения
(5) может принимать любое значение в отрезке [2,054; + ![]() ], при
], при ![]() =0,005 - любое значение в [2,170;
2,576].
=0,005 - любое значение в [2,170;
2,576].
При использовании любого другого расстояния между функциями распределения выводы о неустойчивости правил отбраковки также справедливы. Отметим, что проведенные рассмотрения выполнены в рамках "общей схемы устойчивости" (см. ниже главу об устойчивости статистических процедур).
Рассмотренные примеры показывают, что при конкретном
значении ![]() =
0,01 в неравенстве (4) весьма неустойчивы как уровни значимости при
фиксированном правиле отбраковки, так и параметр d правила отбраковки при
фиксированном уровне значимости. Обсудим, насколько реалистично определение
функции распределения с точностью
=
0,01 в неравенстве (4) весьма неустойчивы как уровни значимости при
фиксированном правиле отбраковки, так и параметр d правила отбраковки при
фиксированном уровне значимости. Обсудим, насколько реалистично определение
функции распределения с точностью ![]()
Есть два подхода к определению функции распределения результатов наблюдений: эвристический подбор с последующей проверкой с помощью критериев согласия и вывод из некоторой вероятностной модели.
Пусть с помощью критерия согласия Колмогорова проверяется
гипотеза о том, что выборка взята из распределения F. Пусть функции
распределения F и G удовлетворяют соотношению (4). Пусть на самом деле выборка
взята из распределения G, а не F. При каких ![]() не удастся различить F и G? Для
определенности, при каких
не удастся различить F и G? Для
определенности, при каких ![]() гипотеза согласия с F будет
приниматься не менее чем в 50% случаев?
гипотеза согласия с F будет
приниматься не менее чем в 50% случаев?
Критерий согласия Колмогорова основан на статистике
![]() (6)
(6)
где расстояние ![]() между функциями распределения
определено выше в формуле (4); H - та функция распределения, согласие с которой
проверяется, а Fn - эмпирическая функция распределения
(т.е. Fn(х) равно доле наблюдений, меньших х, в выборке объема n).
Как показал А.Н. Колмогоров в 1933 г., функция распределения случайной величины
между функциями распределения
определено выше в формуле (4); H - та функция распределения, согласие с которой
проверяется, а Fn - эмпирическая функция распределения
(т.е. Fn(х) равно доле наблюдений, меньших х, в выборке объема n).
Как показал А.Н. Колмогоров в 1933 г., функция распределения случайной величины
![]() при росте
объема выборки n сходится к некоторой функции распределения К(х), которую ныне
называют функцией Колмогорова. При этом К(1,36)= 0,95 и К(0,83)=0,50.
при росте
объема выборки n сходится к некоторой функции распределения К(х), которую ныне
называют функцией Колмогорова. При этом К(1,36)= 0,95 и К(0,83)=0,50.
Поскольку выборка взята из распределения G, то с вероятностью 0,50
![]() (7)
(7)
(при больших n). Тогда для рассматриваемой выборки с учетом неравенства (4) и неравенства треугольника для расстояния Колмогорова и симметричности этого расстояния имеем
![]()
Если
![]()
![]()
т.е.
![]() (8)
(8)
то, согласно формуле (6), гипотеза согласия принимается
по крайней мере с той же вероятностью, с которой выполнено неравенств (7), т.е.
с вероятностью не менее 0,50. Для ![]() = 0,01 это условие выполняется при
n < 2809. Таким образом, для определения функции распределения с точностью
= 0,01 это условие выполняется при
n < 2809. Таким образом, для определения функции распределения с точностью ![]() с помощью
критерия согласия Колмогорова необходимо несколько тысяч наблюдений, что для
большинства эконометрических задач нереально.
с помощью
критерия согласия Колмогорова необходимо несколько тысяч наблюдений, что для
большинства эконометрических задач нереально.
При втором из названных выше подходов к определению
функции распределения ее конкретный вид выводится из некоторой системы аксиом,
в частности, из некоторой модели порождения соответствующей случайной величины.
Например, из модели суммирования вытекает нормальное распределение, а из мультипликативной
модели перемножения - логарифмически нормальное распределение. Как правило, при
выводе используется предельный переход. Так, из Центральной Предельной Теоремы
теории вероятностей вытекает, что сумма независимых случайных величин может
быть приближена нормальным распределением. Однако более детальный анализ, в
частности, с помощью неравенства Берри-Эссеена (см. предыдущий пункт)
показывает, что для гарантированного достижения точности ![]() необходимо более
полутора тысяч слагаемых. Такого количества слагаемых реально, конечно, указать
почти никогда нельзя. Это означает, что при решении практических
эконометрических задач теория дает возможность лишь сформулировать гипотезу о
виде функции распределения, а проверять ее надо с помощью анализа реальной
выборки объема, как показано выше, не менее нескольких тысяч.
необходимо более
полутора тысяч слагаемых. Такого количества слагаемых реально, конечно, указать
почти никогда нельзя. Это означает, что при решении практических
эконометрических задач теория дает возможность лишь сформулировать гипотезу о
виде функции распределения, а проверять ее надо с помощью анализа реальной
выборки объема, как показано выше, не менее нескольких тысяч.
Таким образом, в большинстве реальных ситуаций
определить функцию распределения с точностью ![]() невозможно.
невозможно.
Итак, показано, что правила отбраковки, основанные на использовании конкретной функции распределения, являются крайне неустойчивыми к отклонениям от нее распределения элементов выборки, а гарантировать отсутствие подобных отклонений невозможно. Поэтому отбраковка по классическим правилам математической статистики не является научно обоснованной, особенно при больших объемах выборок. Указанные правила целесообразно применять лишь для выявления "подозрительных" наблюдений, вопрос об отброаковке которых должен решаться из соображений соответствующей предметной области, а не из формально-математических соображений.
Выше для простоты изложения рассмотрен лишь случай полностью известного распределения F, для которого изучено правило отбраковки, заданное формулами (1) и (2). Аналогичные выводы о крайней неустойчивости правил отбраковки справедливы, если "истинное распределение" принадлежит какому-либо параметрическому семейству, например, нормальному, Вейбулла-Гнеденко, гамма.
Параметрическим методам отбраковки, основанным на моделях тех или иных параметрических семейств распределений, посвящены тысячи книг и статей. Приходится признать, что они имеют в основном внутриматематический интерес. При обработке реальных данных следует применять устойчивые методы (см. соответствующую главу), в частности, непараметрические.
Пусть исходные данные –это выборка x1, x2, … , xn , где n – объем выборки. Выборочные значения x1, x2, … , xn рассматриваются как реализации независимых одинаково распределенных случайных величин X1, X2, … , Xn с общей функцией распределения F(x) = P (Xi < x), i = 1,2, …, n. Поскольку функция распределения произвольна (с точностью до условий регулярности типа существования моментов), то рассматриваемые задачи доверительного оценивания характеристик распределения являются непараметрическими. Существование моментов является скорее математическим ограничением, чем реальным, поскольку практически все реальные статистические данные финитны (ограничены сверху и снизу, например, шкалой прибора).
В расчетах будут использоваться выборочное среднее арифметическое
M = (X1 + X2 +… + X n ) / n,
выборочная дисперсия
S2 = { (X1 – M)2 + (X2 – M)2 +… + (X n – M)2 } / (n-1)
и некоторые другие выборочные характеристики, которые мы введем позже.
Точечное и интервальное оценивание математического ожидания. Точечной оценкой для математического ожидания в силу закона больших чисел является выборочное среднее арифметическое М.
M – U(p) S / n1/2 ,
где:
M – выборочное среднее арифметическое,
p – доверительная вероятность (истинное значение математического ожидания находится между нижней доверительной границей и верхней доверительной границей с вероятностью, равной доверительной);
U(p) – число, заданное равенством Ф(U(p)) = (1+ p)/2, где Ф(х) – функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. Например, при p = 95% (т.е. при р = 0,95) имеем U(p) = 1,96. Функция U(p) имеется в большинстве литературных источников по теории вероятностей и математической статистике (см., например, [8]);
S – выборочное среднее квадратическое отклонение (квадратный корень из описанной выше выборочной дисперсии).
M + U(p) S / n1/2 .
С(р) = [n/2 – U(p)n1/2 /2] ,
где [.] – знак целой части числа. Нижняя доверительная граница для медианы имеет вид
Х (С(р)),
где Х(i) – член вариационного ряда с номером i, построенного по исходной выборке (т.е. i-я порядковая статистика). Верхняя доверительная граница для медианы имеет вид
Х (n + 1 - С(р)).
d2 = (m 4 - ((n – 1) /n ) 4 S 4 ) / n ,
где m 4 - выборочный четвертый центральный момент, т.е.
m 4 = { (X1 – M) 4 + (X2 – M) 4 +… + (X n – M) 4 } / n .
Íèæíÿÿ äîâåðèòåëüíàÿ ãðàíèöà äëÿ äèñïåðñèè ñëó÷àéíîé âåëè÷èíû èìååò âèä
S2 - U(p)d ,
где S2 – выборочная дисперсия,
U(p) – квантиль нормального распределения порядка (1+р)/2 (как и раньше),
d – положительный квадратный корень из величины d2, введенной выше.
S2 + U(p)d ,
где все составляющие имеют тот же смысл, что и выше.
При выводе приведенных соотношений используется асимптотическая нормальность выборочной дисперсии, установленная, например, в [10, с.419]. Соответственно доверительный интервал является непараметрическим и асимптотическим. В классическом случае точечная оценка имеет тот же вид, а вот доверительные границы находят с помощью квантилей распределения хи-квадрат с числом степеней свободы, на 1 меньшим объема выборки. Отметим, что в случае нормального распределения четвертый момент в 3 раза больше квадрата дисперсии, а потому можно оценить d2 как (2 S 4 ) / n . Это дает быстрый способ для интервальной оценки дисперсии в нормальном случае.
Точечное и интервальное оценивание среднего квадратического отклонения. Дисперсия рассматриваемой случайной величины - выборочного среднего квадратического отклонения S – оценивается как дробь
d2 / (4 S2 ) .
S - U(p)d / (2S) ,
где S2 – выборочная дисперсия,
U(p) – квантиль нормального распределения порядка (1+р)/2 (как и раньше),
d – положительный квадратный корень из величины d2, введенной выше.
S + U(p)d / (2S) ,
где все составляющие имеют тот же смысл, что и выше.
Правила расчетов настоящего подпункта получены из правил предыдущего подпункта с помощью метода линеаризации (см., например, [11, п.2.4]). В рассматриваемом случае доверительный интервал также является непараметрическим и асимптотическим, а классический подход связан с использованием распределения хи-квадрат.
Точечное и интервальное оценивание коэффициента вариации. Коэффициент вариации широко используется при анализе конкретных экономических данных (поскольку они, как правило, положительны), но не очень популярен среди теоретиков. Дисперсия выборочного коэффициента вариации
Vn = S / M
D2 = (Vn4 - Vn 2 / 4 + m 4 / (4 S 2 M 2) - m 3 /M 3 ) / n ,
где М – выборочное среднее арифметическое,
S 2 – выборочная дисперсия,
m 3 - выборочный третий центральный момент, т.е.
m 3 = { (X1 – M) 3 + (X2 – M) 3 +… + (X n – M) 3 } / n ,
m 4 - выборочный четвертый центральный момент (см. выше),
Vn – выборочный коэффициент вариации,
n - объем выборки.
Vn - U(p) D,
где Vn – выборочный коэффициент вариации,
U(p) – квантиль нормального распределения порядка (1+р)/2 (как и ранее),
D – положительный квадратный корень из величины D2, введенной выше.
Vn + U(p) D,
где все составляющие имеют тот же смысл, что и выше.
Как и в предыдущих случаях, доверительный интервал является непараметрическим и асимптотическим. Он получен в результате применения специальной технологии вывода асимптотических соотношений прикладной статистики. Эта технология в качестве первого шага использует многомерную центральную предельную теорему, примененную к сумме векторов, координаты которых – степени исходных случайных величин. Второй шаг – преобразование предельного многомерного нормального вектора с целью получения интересующего исследователя вектора. При этом используются соображения линеаризации и отбрасываются бесконечно малые величины. Третий шаг – строгое обоснование полученных результатов на стандартном для асимптотических математико-статистических рассуждений уровне. При этом обычно оказывается необходимым использовать необходимые и достаточные условия наследования сходимости, полученные в монографии [11, п.2.4]. Именно таким образом были получены приведенные выше результаты для выборочного коэффициента вариации. Формулы оказались существенно более сложными, чем в предыдущих случаях. Это объясняется тем, что выборочный коэффициент вариации - функция двух выборочных моментов, а ранее рассматривались либо выборочные моменты поодиночке, либо функция от одного выборочного момента - выборочной дисперсии.
О проверке однородности двух независимых выборок
Противоположным понятием является «различие». Можно переформулировать задачу: требуется проверить, есть ли различие между выборками. Если различия нет, то для дальнейшего изучения часто выборки объединяют.
Например, в маркетинге важно выделить сегменты потребительского рынка. Если установлена однородность двух выборок, то возможно объединение сегментов, из которых они взяты, в один. В дальнейшем это позволит осуществлять по отношению к ним одинаковую маркетинговую политику (проводить одни и те же рекламные мероприятия и т.п.). Если же установлено различие, то поведение потребителей в двух сегментах различно, объединять эти сегменты нельзя, и могут понадобиться различные маркетинговые стратегии, своя для каждого из этих сегментов.
Традиционный метод проверки однородности (критерий Стьюдента). Для дальнейшего критического разбора опишем традиционный статистический метод проверки однородности. Вычисляют средние арифметические в каждой выборке
 ,
,
затем выборочные дисперсии
![]() ,
, ![]()
и статистику Стьюдента t, на основе которой принимают решение,
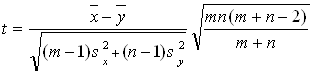 . (1)
. (1)
По заданному уровню значимости a и числу степеней свободы (m+n _ 2) из таблиц распределения Стьюдента находят критическое значение tкр. Если |t|>tкр, то гипотезу однородности (отсутствия различия) отклоняют, если же |t|<tкр, то принимают. (При односторонних альтернативных гипотезах вместо условия |t|>tкр проверяют, что t>tкр; эту постановку рассматривать не будем, так как в ней нет принципиальных отличий от обсуждаемой здесь.)
Рассмотрим условия применимости традиционного метода проверки однородности, основанного на использовании статистики t Стьюдента, а также укажем более современные методы.
Вероятностная модель порождения данных. Для обоснованного применения эконометрических методов необходимо прежде всего построить и обосновать вероятностную модель порождения данных. При проверке однородности двух выборок общепринята модель, в которой x1, x2,...,xm рассматриваются как результаты m независимых наблюдений некоторой случайной величины Х с функцией распределения F(x), неизвестной статистику, а y1, y2,...,yn - как результаты п независимых наблюдений, вообще говоря, другой случайной величины Y с функцией распределения G(x), также неизвестной статистику. Предполагается также, что наблюдения в одной выборке не зависят от наблюдений в другой, поэтому выборки и называют независимыми.
Возможность применения модели в конкретной реальной ситуации требует обоснования. Независимость и одинаковая распределенность результатов наблюдений, входящих в выборку, могут быть установлены или исходя из методики проведения конкретных наблюдений, или путем проверки статистических гипотез независимости и одинаковой распределенности с помощью соответствующих критериев [8].
Если проведено (т+п) измерений объемов продаж в (т+п) торговых точках, то описанную выше модель, как правило, можно применять. Если же, например, xi и yi - объемы продаж одного и того же товара до и после определенного рекламного воздействия, то рассматриваемую модель применять нельзя. (В этом случае используют модель т.н. связанных выборок, в которой обычно строят новую выборку zi = xi - yi и используют статистические методы анализа одной выборки, а не двух. Проверка однородности для связанных выборок рассматривается ниже.)
При дальнейшем изложении принимаем описанную выше вероятностную модель двух выборок.
Уточнения понятия однородности. Понятие «однородность», т. е. «отсутствие различия», может быть формализовано в терминах вероятностной модели различными способами.
Наивысшая степень однородности достигается, если обе выборки взяты из одной и той же генеральной совокупности, т. е. справедлива нулевая гипотеза
H0 : F(x)=G(x) при всех х.
Отсутствие однородности означает, что верна альтернативная гипотеза, согласно которой
H1 : F(x0)¹G(x0)
хотя бы при одном значении аргумента x0. Если гипотеза H0 принята, то выборки можно объединить в одну, если нет - то нельзя.
В некоторых случаях целесообразно проверять не совпадение функций распределения, а совпадение некоторых характеристик случайных величин Х и Y - математических ожиданий, медиан, дисперсий, коэффициентов вариации и др. Например, однородность математических ожиданий означает, что справедлива гипотеза
H'0 : M(X)=M(Y),
где M(Х) и M(Y) - математические ожидания случайных величин Х и Y, результаты наблюдений над которыми составляют первую и вторую выборки соответственно. Доказательство различия между выборками в рассматриваемом случае - это доказательство справедливости альтернативной гипотезы
H'1 : M(X) ¹ M(Y) .
Если гипотеза H0 верна, то и гипотеза H'0 верна, но из справедливости H'0 не следует справедливость H0 . В частности, если в результате обработки выборочных данных принята гипотеза H'0, то отсюда не следует, что две выборки можно объединить в одну. Однако в ряде ситуаций целесообразна проверка именно гипотезы H'0 . Например, пусть функция спроса на определенный товар или услугу оценивается путем опроса потребителей (первая выборка) или с помощью данных о продажах (вторая выборка). Тогда маркетологу важно проверить гипотезу об отсутствии систематических расхождений результатов этих двух методов, т.е. гипотезу о равенстве математических ожиданий. Другой пример – из производственного менеджмента. Пусть изучается эффективность управления бригадами рабочих на предприятии с помощью двух организационных схем, результаты наблюдения - объем производства на одного члена бригады, а показатель эффективности организационной схемы - средний (по предприятию) объем производства на одного рабочего. Тогда для сравнения эффективности препаратов достаточно проверить гипотезу H'0 .
Классические условия применимости критерия Стьюдента. Пусть выполнены два классических условия применимости критерия Стьюдента, основанного на использовании статистики t, заданной формулой (1):
а) результаты наблюдений имеют нормальные распределения:
F(x)=N(x; m1, s12), G(x)=N(x; m2, s22)
с математическими ожиданиями m1 и m2 и дисперсиями s12 и s22 в первой и во второй выборках соответственно;
б) дисперсии результатов наблюдений в первой и второй выборках совпадают:
D(X)=s12=D(Y)=s22.
Если условия а) и б) выполнены, то нормальные распределения F(x) и G(x) отличаются только математическими ожиданиями, а поэтому обе гипотезы H0 и H'0 сводятся к гипотезе
H"0 : m1=m2, ,
а обе альтернативные гипотезы H1 и H'1 сводятся к гипотезе
H"1 : m1¹m2, .
Если условия а) и б) выполнены, то статистика t при справедливости H"0 имеет распределение Стьюдента с (т + п - 2) степенями свободы. Только в этом случае описанный выше традиционный метод обоснован безупречно. Если хотя бы одно из условий а) и б) не выполнено, то нет оснований считать, что статистика t имеет распределение Стьюдента, поэтому применение традиционного метода, строго говоря, не обосновано. Обсудим возможность проверки этих условий и последствия их нарушений.
О проверке условия нормальности. Априори нет оснований предполагать нормальность распределения результатов экономических, технико-экономических и иных наблюдений. Следовательно, нормальность надо проверять. Разработано много статистических критериев для проверки нормальности распределения результатов наблюдений [8]. Однако проверка нормальности - более сложная и трудоемкая статистическая процедура, чем проверка однородности (как с помощью статистики t Стьюдента, так и с использованием непараметрических критериев, рассматриваемых ниже).
Для достаточно надежного установления нормальности требуется весьма большое число наблюдений. Выше показано, что для того, чтобы гарантировать, что функция распределения результатов наблюдений отличается от некоторой нормальной не более чем на 0,01 (при любом значении аргумента), требуется порядка 2500 наблюдений. В большинстве экономических и технико-экономических исследований число наблюдений существенно меньше.
Как уже отмечалось, есть и одна общая причина отклонений от нормальности: любой результат наблюдения записывается конечным (обычно 2-5) количеством цифр, а с математической точки зрения вероятность такого события равна 0. Из сказанного выше следует, что в эконометрике распределение результатов экономических и технико-экономических наблюдений практически всегда более или менее отличается от нормального. Более подробно это утверждение выше.
Последствия нарушения условия нормальности. Если условие а) не выполнено, то распределение статистики t не является распределением Стьюдента. Однако при справедливости H'0 и условии б) распределение статистики t при росте объемов выборок приближается к стандартному нормальному распределению Ф(х)=N(x; 0, 1). К этому же распределению приближается распределение Стьюдента при возрастании числа степеней свободы. Другими словами, несмотря на нарушение условия нормальности традиционный метод (критерий Стьюдента) можно использовать для проверки гипотезы H'0 при больших объемах выборок. При этом вместо таблиц распределения Стьюдента достаточно пользоваться таблицами стандартного нормального распределения Ф(х).
Сформулированное в предыдущем абзаце утверждение справедливо для любых функций распределения F(x) и G(x) таких, что M(X)=M(Y), D(X)=D(Y) и выполнены некоторые внутриматематические условия, обычно считающиеся справедливыми в реальных задачах. Если же M(X)¹M(Y), то нетрудно вычислить, что при больших объемах выборок
P(t<x)»Ф(x-amn), (2)
где
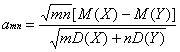 . (3)
. (3)
Формулы (2) - (3) позволяют приближенно вычислять мощность t-критерия (точность возрастает при увеличении т и п).
О проверке условия равенства дисперсий. Иногда условие б) вытекает из методики получения результатов наблюдений, например, когда с помощью одного и того же прибора или методики m раз измеряют характеристику первого объекта и п раз-второго, а параметры распределения погрешностей измерения при этом не меняются. Однако ясно, что в постановках большинства исследовательских и практических задач нет основании априори предполагать равенство дисперсий.
Целесообразно ли проверять равенство дисперсий статистическими методами, например, как это иногда предлагают, с помощью F-критерия Фишера? Этот критерий основан на нормальности распределений результатов наблюдений, от которой неизбежны отклонения (см. выше), причем хорошо известно, что в отличие от t-критерия его распределение сильно меняется при малых отклонениях от нормальности [10]. Кроме того, F-критерий отвергает гипотезу D(X)=D(Y) лишь при большом различии выборочных дисперсий. Так, для данных [8] о двух группах результатов химических анализов отношение выборочных дисперсий равно 1,95, т.е. существенно отличается от 1. Тем не менее гипотеза о равенстве теоретических дисперсий принимается на 1% уровне значимости. Следовательно, при проверке однородности применение F-критерия для предварительной проверки равенства дисперсий нецелесообразно.
Итак, в большинстве экономических и технико-экономических задач условие б) нельзя считать выполненным, а проверять его нецелесообразно.
Последствия нарушения условия равенства дисперсий. Если объемы выборок т и п велики, то можно показать, что распределение статистики t описывается с помощью только математических ожиданий M(Х) и M(Y), дисперсий D(X), D(Y) и отношения объемов выборок, а именно:
P(t<x)»Ф(bmnx-amn), (4)
где amn определено формулой (3),
![]() . (5)
. (5)
Если bmn¹1, то распределение статистики t отличается от распределения, заданного формулой (2), полученной в предположении равенства дисперсий. Когда bmn=1? В двух случаях - при m = n и при D(X) = D(Y). Таким образом, при больших и равных объемах выборок требовать выполнения условия б) нет необходимости. Кроме того, ясно, что если объемы выборок мало различаются, то bmn близко к 1. Так, для данных [8] имеем b*mn= 0,987, где b*mn - оценка bmn, полученная заменой в формуле (5) теоретических дисперсий на выборочные.
Область применимости традиционного метода проверки однородности с помощью критерия Стьюдента. Подведем итоги рассмотрения t-критерия. Он позволяет проверять гипотезу H'0 о равенстве математических ожиданий, но не гипотезу H0 о том, что обе выборки взяты из одной и той же генеральной совокупности. Классические условия применимости критерия Стьюдента в подавляющем большинстве экономических и технико-экономических задач не выполнены. Тем не менее при больших и примерно равных объемах выборок его можно применять. При конечных объемах выборок традиционный метод носит неустранимо приближенный характер.
Критерий Крамера-Уэлча равенства математических ожиданий
Вместо критерия Стьюдента предлагаем для проверки H'0 использовать критерий Крамера-Уэлча [12], основанный на статистике
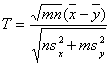 . (6)
. (6)
Критерий Крамера-Уэлча имеет прозрачный смысл – разность выборочных средних арифметических для двух выборок делится на естественную оценку среднего квадратического отклонения этой разности. Естественность указанной оценки состоит в том, что неизвестные статистику дисперсии заменены их выборочными оценками. Из многомерной центральной предельной теоремы и из теорем о наследовании сходимости [11] вытекает, что при росте объемов выборок распределение статистики Т Крамера-Уэлча сходится к стандартному нормальному распределению с математическим ожиданием 0 и дисперсией 1. Итак, при справедливости H'0 и больших объемах выборок распределение статистики Т приближается с помощью стандартного нормального распределения Ф(х), из таблиц которого следует брать критические значения.
При т=п, как следует из формул (1) и (6), t=T. При т¹п этого равенства нет. В частности, при sx2 в (1) стоит множитель (m-1), а в (6)- множитель п.
Если M(X)¹M(Y), то при больших объемах выборок
P(T<X)»Ф(x-cmn), (7)
где
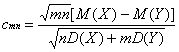 . (8)
. (8)
При т=п или D(X)=D(Y), согласно формулам (3) и (8), amn=cmn , в остальных случаях равенства нет.
Из асимптотической нормальности статистики Т, формул (7) и (8) следует, что правило принятия решения для критерия Крамера-Уэлча выглядит так:
-
если
|T|<![]() то
гипотеза однородности (равенства) математических ожиданий принимается на уровне
значимости
то
гипотеза однородности (равенства) математических ожиданий принимается на уровне
значимости ![]()
-
если
же |T|>![]() то
гипотеза однородности (равенства) математических ожиданий отклоняется на уровне
значимости
то
гипотеза однородности (равенства) математических ожиданий отклоняется на уровне
значимости ![]() .
.
В
эконометрике наиболее часто применяется уровень значимости ![]() Тогда значение модуля
статистики Т Крамера-Уэлча надо сравнивать с граничным значением
Тогда значение модуля
статистики Т Крамера-Уэлча надо сравнивать с граничным значением![]()
Из сказанного выше следует, что применение критерия Крамера-Уэлча не менее обосновано, чем применение критерия Стьюдента. Дополнительное преимущество - не требуется равенства дисперсий D(X)=D(Y). Распределение статистики Т не является распределением Стьюдента, однако и распределение статистики t, как показано выше, не является таковым в реальных ситуациях.
Распределение статистики Т при объемах выборок т=п=6, 8, 10, 12 и различных функциях распределений выборок F(x) и G(x) изучено нами совместно с Ю.Э. Камнем и Я.Э. Камнем методом статистических испытаний (Монте-Карло). Рассмотрены различные варианты функций распределения F(x) и G(x). Результаты показывают, что даже при таких небольших объемах выборок точность аппроксимации предельным стандартным нормальным распределением вполне удовлетворительна. Поэтому представляется целесообразным во всех тех случаях, когда в настоящее время используется критерий Стьюдента, заменить его на критерий Крамера-Уэлча. Конечно, такая замена потребует переделки ряда нормативно-технических и методических документов, исправления учебников и учебных пособий для вузов.
Пример.
Пусть объем первой выборки ![]() Для второй выборки
Для второй выборки ![]() Вычислим величину
статистики Крамера-Уэлча
Вычислим величину
статистики Крамера-Уэлча
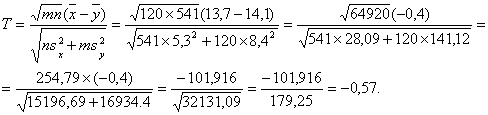
Поскольку полученное значение по абсолютной величине меньше 1,96, то гипотеза однородности математических ожиданий принимается на уровне значимости 0,05.
Непараметрические методы проверки однородности. В большинстве экономических и технико-экономических задач представляет интерес не проверка равенства математических ожиданий или иных характеристик распределения, а обнаружение различия генеральных совокупностей, из которых извлечены выборки, т.е. проверка гипотезы H0. Методы проверки гипотезы H0 позволяют обнаружить не только изменение математического ожидания, но и любые иные изменения функции распределения результатов наблюдений при переходе от одной выборки к другой (увеличение разброса, появление асимметрии и т. д.). Как установлено выше, методы, основанные на использовании статистик t Стьюдента и Т Крамера-Уэлча, не позволяют проверять гипотезу H0 . Априорное предположение о принадлежности функций распределения F(x) и G(x) к какому-либо определенному параметрическому семейству (например, семействам нормальных, логарифмически нормальных, распределений Вейбулла-Гнеденко, гамма-распределений и др.), как показано выше, обычно нельзя достаточно надежно обосновать. Поэтому для проверки H0 следует использовать методы, пригодные при любом виде F(x) и G(x), т.е. непараметрические методы. (Термин «непараметрический метод» означает, что при использовании этого метода нет необходимости предполагать, что функции распределения результатов наблюдений принадлежат какому-либо определенному параметрическому семейству.)
Для проверки гипотезы H0 разработано много непараметрических методов - критерии Смирнова, типа омега-квадрат (Лемана-Розенблатта), Вилкоксона (Манна-Уитни), Ван-дер-Вардена, Сэвиджа, хи-квадрат и др. [8, 9, 13]. Распределения статистик всех этих критериев при справедливости H0 не зависят от конкретного вида совпадающих функций распределения F(x)ºG(x). Следовательно, таблицами точных и предельных (при больших объемах выборок) распределений статистик этих критериев и их процентных точек [8, 9] можно пользоваться при любых непрерывных функциях распределения результатов наблюдений.
Каким из непараметрических критериев пользоваться? Как известно [10], для выбора одного из нескольких критериев необходимо сравнить их мощности, определяемые видом альтернативных гипотез. Сравнению мощностей критериев посвящена обширная литература.
Хорошо изучены свойства критериев при альтернативной гипотезе сдвига
H1c : G(x)=F(x-d), d¹0.
Критерии Вилкоксона, Ван-дер-Вардена и ряд других ориентированы для применения именно в этой ситуации. Если m раз измеряют характеристику одного объекта и п раз - другого, а функция распределения погрешностей измерения произвольна, но не меняется при переходе от объекта к объекту (это более жесткое требование, чем условие равенства дисперсий), то рассмотрение гипотезы H1c оправдано. Однако в большинстве экономических и технико-экономических исследований нет оснований считать, что функции распределения, соответствующие выборкам, различаются только сдвигом.
Какие гипотезы можно проверять с помощью двухвыборочного критерия Вилкоксона?
Покажем (и это - основной результат настоящего пункта), что двухвыборочный критерий Вилкоксона (в литературе его называют также критерием Манна-Уитни) предназначен для проверки гипотезы
H0 : P(X < Y) = 1/2,
где X - случайная величина, распределенная как элементы первой выборки, а Y - второй.
В описанной выше вероятностной модели двух независимых выборок без ограничения общности можно считать, что объем первой из них не превосходит объема второй, m < n, в противном случае выборки можно поменять местами. Обычно предполагается, что функции F(x) и G(x) непрерывны и строго возрастают. Из непрерывности этих функций следует, что с вероятностью 1 все m + n результатов наблюдений различны. В реальных эконометрических данных иногда встречаются совпадения, но сам факт их наличия - свидетельство нарушений предпосылок только что описанной базовой математической модели.
Статистика S двухвыборочного критерия Вилкоксона определяется следующим образом. Все элементы объединенной выборки X1, X2, ..., Xm, Y1, Y2, ..., Yn упорядочиваются в порядке возрастания. Элементы первой выборки X1, X2, ..., Xm занимают в общем вариационном ряду места с номерами R1, R2, ..., Rm, другими словами, имеют ранги R1, R2, ..., Rm . Тогда статистика Вилкоксона - это сумма рангов элементов первой выборки
S = R1 + R2 + ... + Rm .
Статистика U Манна-Уитни определяется как число пар (Xi, Yj) таких, что Xi < Yj , среди всех mn пар, в которых первый элемент - из первой выборки, а второй - из второй. Как известно [13, с.160],
U = mn + m(m+1)/2 - S .
Поскольку S и U линейно связаны, то часто говорят не о двух критериях - Вилкоксона и Манна-Уитни, а об одном - критерии Вилкоксона (Манна-Уитни).
Критерий Вилкоксона - один из самых известных инструментов непараметрической статистики (наряду со статистиками типа Колмогорова-Смирнова и коэффициентами ранговой корреляции). Свойствам этого критерия и таблицам его критических значений уделяется место во многих монографиях по математической и прикладной статистике (см., например, [8, 9, 13]).
Однако в литературе имеются и неточные утверждения относительно возможностей критерия Вилкоксона. Так, одни полагают, что с его помощью можно обнаружить любое различие между функциями распределения F(x) и G(x). По мнению других, этот критерий нацелен на проверку равенства медиан распределений, соответствующих выборкам. И то, и другое, строго говоря, неверно. Это будет ясно из дальнейшего изложения.
Введем некоторые обозначения. Пусть F-1(t) - функция, обратная к функции распределения F(x). Она определена на отрезке [0;1]. Положим L(t) = G(F-1(t)). Поскольку F(x) непрерывна и строго возрастает, то F-1(t) и L(t) обладают теми же свойствами. Важную роль в дальнейшем изложении будет играть величина a = P(X< Y) . Как нетрудно показать,
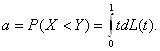
Введем также параметры
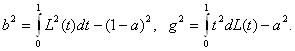
Тогда математические ожидания и дисперсии статистик Вилкоксона и Манна-Уитни согласно [13, с.160] выражаются через введенные величины:
М(U) = mna , М(S) = mn + m(m+1)/2 - М(U) = mn(1- a) + m(m+1)/2,
D(S) = D(U) = mn [ (n - 1) b2 + (m - 1) g2 + a(1 -a) ] . (1)
Когда объемы обеих выборок безгранично растут, распределения статистик Вилкоксона и Манна-Уитни являются асимптотически нормальными (см., например, [13, гл.5 и 6]) с параметрами, задаваемыми формулами (1) .
Если выборки полностью однородны, т.е. их функции распределения совпадают, справедлива гипотеза
H0: F(x) = G(x) при всех x, (2)
то L(t) = t и a= 1/2. Подставляя в формулы (1), получаем, что
М(S) = m(m+n+1)/2, D(S) = mn(m+n+1)/ 12 (3) .
Следовательно, распределение нормированной и центрированной статистики Вилкоксона
T = ( S - m(m+n+1)/2) (mn(m+n+1)/ 12 ) - 1/2 (4)
при росте объемов выборок приближается к стандартному нормальному распределению (с математическим ожиданием 0 и дисперсией 1).
Из асимптотической нормальности статистики Т следует, что правило принятия решения для критерия Вилкоксона выглядит так:
-
если
|T|<![]() то
гипотеза (2) однородности (тождества) функций распределений принимается на
уровне значимости
то
гипотеза (2) однородности (тождества) функций распределений принимается на
уровне значимости ![]()
-
если
же |T|>![]() то
гипотеза (2) однородности (тождества) функций распределений отклоняется на
уровне значимости
то
гипотеза (2) однородности (тождества) функций распределений отклоняется на
уровне значимости ![]() .
.
В
эконометрике наиболее часто применяется уровень значимости ![]() Тогда значение модуля
статистики Т Вилкоксона надо сравнивать с граничным значением
Тогда значение модуля
статистики Т Вилкоксона надо сравнивать с граничным значением![]()
Пример 1. Пусть даны две выборки. Первая содержит m= 12 элементов 17; 22; 3; 5; 15; 2; 0; 7; 13; 97; 66; 14. Вторая содержит n=14 элементов 47; 30; 2; 15; 1; 21; 25; 7; 44; 29; 33; 11; 6; 15. Проведем проверку однородности функций распределения двух выборок с помощью только что сформулированного правила принятия решений на основе критерия Вилкоксона.
Первым шагом является построение общего вариационного ряда для элементов двух выборок (табл.1).
Табл.1. Общий вариационный ряд для элементов двух выборок
| Ранги | 1 | 2 | 3,5 | 3,5 | 5 | 6 | 7 | 8,5 | 8,5 | 10 | 11 | 12 | 14 |
| Элементы выборок | 0 | 1 | 2 | 2 | 3 | 5 | 6 | 7 | 7 | 11 | 13 | 14 | 15 |
| Номера выборок | 1 | 2 | 1 | 2 | 1 | 1 | 2 | 1 | 2 | 2 | 1 | 1 | 1 |
| Ранги | 14 | 14 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| Элементы выборок | 15 | 15 | 17 | 21 | 22 | 25 | 29 | 30 | 33 | 44 | 47 | 66 | 97 |
| Номера выборок | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 |
Хотя с точки зрения теории математической статистики вероятность совпадения двух элементов выборок равна 0, в реальных выборках экономических данных совпадения встречаются. Так, в рассматриваемых выборках, как видно из табл.1, два раза повторяется величина 2, два раза - величина 7 и три раза - величина 15. В таких случаях говорят о наличии "связанных рангов", а соответствующим совпадающим величинам приписывают среднее арифметическое тех рангов которые они занимают. Так, величины 2 и 2 занимают в объединенной выборке места 3 и 4, поэтому им приписывается ранг (3+4)/2=3,5. Величины 7 и 7 занимают в объединенной выборке места 8 и 9, поэтому им приписывается ранг (8+9)/2=8,5. Величины 15, 15 и 15 занимают в объединенной выборке места 13, 14 и 15, поэтому им приписывается ранг (13+14+15)/3=14.
Следующий шаг - подсчет значения статистики Вилкоксона, т.е. суммы рангов элементов первой выборки
S = R1 + R2 + ... + Rm = 1+3,5+5+6+8,5+11+12+14+16+18+25+26=146.
Подсчитаем также сумму рангов элементов второй выборки
S1 = 2+3,5+7+8,5+10+14+14+17+19+20+21+22+23+24= 205.
Величина S1 может быть использована для контроля вычислений. Дело в том, что суммы рангов элементов первой выборки S и второй выборки S1 вместе составляют сумму рангов объединенной выборки, т.е. сумму всех натуральных чисел от 1 до m+n. Следовательно,
S+ S1 = (m+n)(m+n+1)/2= (12+14)(12+14+1)/2= 351.
В соответствии с ранее проведенными расчетами S+S1 = 146+205=351. Необходимое условие правильности расчетов выполнено. Ясно, что справедливость этого условия не гарантирует правильности расчетов.
Перейдем к расчету статистики Т. Согласно формуле (3)
М(S) = 12(12+14+1)/ 2 = 162, D(S) = 12.14(12+14+1)/ 12= 378 .
Следовательно,
T = ( S - 162) (378 ) - 1/2 = (146-162) / 19,44 = - 0.82.
Поскольку |T|<1,96, то гипотеза однородности принимается на уровне значимости0,05.
Что будет, если поменять выборки местами, вторую назвать первой? Тогда вместо S надо рассматривать S1 . Имеем
М(S1 ) = 14(12+14+1)/ 2 = 189, D(S) = D(S1 ) = 378 ,
T1 = ( S1 - 189) (378 ) - 1/2 = (205-162) / 19,44 = 0.82.
Таким образом, значения статистики критерия отличаются только знаком (можно показать, что это утверждение верно всегда). Поскольку в правиле принятия решения используется только абсолютная величина статистики, то принимаемое решение не зависит от того, какую выборку считаем первой, а какую второй. Для уменьшения объема таблиц принято считать первой выборку меньшего объема.
Продолжим обсуждение критерия Вилкоксона. Правила принятия решений и таблица критических значений для критерия Вилкоксона строятся в предположении справедливости гипотезы полной однородности, описываемой формулой (2). А что будет, если эта гипотеза неверна? Другими словами, какова мощность критерия Вилкоксона?
Пусть объемы выборок достаточно велики, так что можно пользоваться асимптотической нормальностью статистики Вилкоксона. Тогда в соответствии с формулами (1) статистика T будет асимптотически нормальна с параметрами
М(T) = ( 12mn ) 1/2 (1/2 - a) (m+n+1) - 1/2 ,
D(T) = 12 [(n - 1) b2 + (m - 1) g2 + a(1 -a) ] (m+n+1) - 1 . (5)
Из формул (5) видно большое значение гипотезы
H01: a = P(X < Y) = 1/2 . (6)
Если эта гипотеза неверна, то, поскольку m < n, справедлива оценка
|M(T)| > (12m n (2n+1) - 1) 1/2 |1/2 - a| ,
а потому |E(T)| безгранично растет при росте объемов выборок. В то же время, поскольку
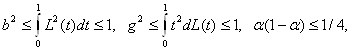
то
D(T) < 12 [(n - 1) + (m - 1) + 1/4] (m+n+1) - 1 <12. (7)
Следовательно, вероятность отклонения гипотезы H01 , когда она неверна, т.е. мощность критерия Вилкоксона как критерия проверки гипотезы (6), стремится к 1 при возрастании объемов выборок, т.е. критерий Вилкоксона является состоятельным для этой гипотезы при альтернативе
АH01:
a = P(X < Y) ![]() 1/2 .
(8) .
1/2 .
(8) .
Если же гипотеза (6) верна, то статистика T асимптотически нормальна с математическим ожиданием 0 и дисперсией, определяемой формулой
D(T) = 12 [(n - 1) b2 + (m - 1) g2 + 1/4 ] (m+n+1) -1 . (9)
Гипотеза (6) является сложной, дисперсия (9), как показывают приводимые ниже примеры, в зависимости от значений b2 и g2 может быть как больше 1, так и меньше 1, но согласно неравенству (7) никогда не превосходит 12.
Приведем пример двух функций распределения F(x) и G(x) таких, что гипотеза (6) выполнена, а гипотеза (2) - нет. Поскольку
a
= P(X < Y) = ![]() , 1 - a = P(Y < X) =
, 1 - a = P(Y < X) = ![]() (10)
(10)
и a = 1/2 в случае справедливости гипотезы (2), то для выполнения условия (6) необходимо и достаточно, чтобы
![]() (11)
,
(11)
,
а потому естественно в качестве F(x) рассмотреть функцию равномерного распределения на интервале (-1 ; 1). Тогда формула (11) переходит в условие
![]() (11)
.
(11)
.
Это условие выполняется, если функция (G(x) - (x + 1)/2 ) является нечетной.
Пример 2. Пусть функции распределения F(x) и G(x) сосредоточены на интервале (-1 ; 1), на котором
F(x)
= (x + 1)/2 , G(x) = ( x + 1 + 1/![]() sin
sin
![]() x ) / 2 .
x ) / 2 .
Тогда
x=F-1(t)=2
-1, L(t)=G(F-1(t))=(2t+1/![]() sin
sin![]() (2t-1))/2=t+1/2
(2t-1))/2=t+1/2![]() sin
sin![]() (2t-1) .
(2t-1) .
Условие (11) выполнено, поскольку функция (G(x) - (x + 1)/2) является нечетной. Следовательно, a = 1/2 . Начнем с вычисления
g2
= 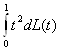 - 1/4 =
- 1/4 =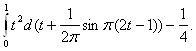
Поскольку
![]()
то
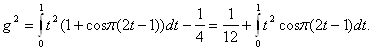
С помощью замены переменных t = (x +1) / 2 получаем, что
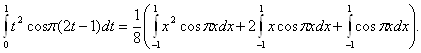
В
правой части последнего равенства стоят табличные интегралы (см., например,
справочник [14, с.71]. Проведя соответствующие вычисления, получаем, что в
правой части стоит 1/8 ( - 4/ ![]() 2) = - 1/(2
2) = - 1/(2 ![]() 2). Следовательно,
2). Следовательно,
g2
= 1/12 - 1/(2 ![]() 2) = 0,032672733...
2) = 0,032672733...
Перейдем к вычислению b2. Поскольку
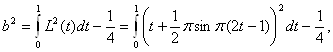
то
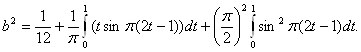
С помощью замены переменных t = (x+1)/2 переходим к табличным интегралам (см., например, справочник [14, с.65]):
![]()
Проведя необходимые вычисления, получим, что
![]()
Следовательно, для рассматриваемых функций распределения нормированная и центрированная статистика Вилкоксона (см. формулу (4)) асимптотически нормальна с математическим ожиданием 0 и дисперсией (см. формулу (9))
D(T) = ( 0,544 n + 0,392 m + 2,064 ) (m+n+1) - 1 .
Как легко видеть, дисперсия всегда меньше 1. Это значит, что в рассматриваемом случае гипотеза полной однородности (2) при проверке с помощью критерия Вилкоксона будет приниматься чаще, чем если она на самом деле верна.
На наш взгляд, это означает, что критерий Вилкоксона нельзя считать критерием для проверки гипотезы (2) при альтернативе общего вида. Он не всегда позволяет проверить однородность - не при всех альтернативах. Точно так же критерии типа хи-квадрат нельзя считать критериями проверки гипотез согласия и однородности - они позволяют обнаружить не все различия, поскольку некоторые из них "скрадывает" группировка.
Обсудим теперь, действительно ли критерий Вилкоксона нацелен на проверку равенства медиан распределений, соответствующих выборкам.
Пример
3.
Построим
семейство пар функций распределения F(x) и G(x) таких, что их медианы различны,
но для F(x) и G(x) выполнена гипотеза (6). Пусть распределения сосредоточены на
интервале (0 ; 1), и на нем G(x) = x , а F(x) имеет кусочно-линейный график с
вершинами в точках (0 ; 0), (![]() , 1/2 ), (
, 1/2 ), (![]() , 3/4), (1 ; 1). Следовательно,
, 3/4), (1 ; 1). Следовательно,
F(x) = 0 при x < 0 ;
F(x)
= x / (2 ![]() )
на [0 ;
)
на [0 ; ![]() ) ;
) ;
F(x)
= 1/2 + (x - ![]() ) / (4
) / (4 ![]() - 4
- 4 ![]() ) на [
) на [![]() ;
; ![]() ) ;
) ;
F(x)
= 3/4 + (x - ![]() ) / (4 - 4
) / (4 - 4 ![]() ) на [
) на [![]() ; 1] ;
; 1] ;
F(x) = 1 при x > 1.
Очевидно,
что медиана F(x) равна ![]() , а медиана G(x) равна 1/2 .
, а медиана G(x) равна 1/2 .
Согласно
соотношению (9) для выполнения гипотезы (6) достаточно определить ![]() как функцию
как функцию ![]() ,
, ![]() =
= ![]() (
(![]() ) , из условия
) , из условия
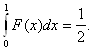
Вычисления дают
![]() =
= ![]() (
(![]() ) = 3 (1 -
) = 3 (1 - ![]() )/2 .
)/2 .
Учитывая,
что ![]() лежит
между
лежит
между ![]() и
1, не совпадая ни с тем, ни с другим, получаем ограничения на
и
1, не совпадая ни с тем, ни с другим, получаем ограничения на ![]() , а именно, 1/3 <
, а именно, 1/3 < ![]() < 3/5 .
Итак, построено искомое семейство пар функций распределения.
< 3/5 .
Итак, построено искомое семейство пар функций распределения.
Пример
4.
Пусть,
как и в примере 3, распределения сосредоточены на интервале (0; 1), и на нем F(x)=x,
а G(x) - функция распределения, сосредоточенного в двух точках - ![]() и 1, т.е. G(x) = 0 при x,
не превосходящем
и 1, т.е. G(x) = 0 при x,
не превосходящем ![]() ; G(x) = h на (
; G(x) = h на (![]() ; 1] ; G(x) = 1 при x
> 1. С такой функцией G(x) легко проводить расчеты. Однако она не удовлетворяет
принятым выше условиям непрерывности и строгого возрастания. Вместе с тем легко
видеть, что она является предельной (сходимость в каждой точке отрезка [0 ; 1]
) для последовательности функций распределения, удовлетворяющих этим условиям,
а распределение статистики Вилкоксона для пары функций распределения примера 4
является предельным для последовательности соответствующих распределений
статистики Вилкоксона, полученных в рассматриваемых условиях непрерывности и
строгого возрастания.
; 1] ; G(x) = 1 при x
> 1. С такой функцией G(x) легко проводить расчеты. Однако она не удовлетворяет
принятым выше условиям непрерывности и строгого возрастания. Вместе с тем легко
видеть, что она является предельной (сходимость в каждой точке отрезка [0 ; 1]
) для последовательности функций распределения, удовлетворяющих этим условиям,
а распределение статистики Вилкоксона для пары функций распределения примера 4
является предельным для последовательности соответствующих распределений
статистики Вилкоксона, полученных в рассматриваемых условиях непрерывности и
строгого возрастания.
Условие
P(X < Y) = 1/2 выполнено, если h = (1 -![]() )-1 / 2 (при
)-1 / 2 (при ![]() из отрезка [0 ; 1/2] ).
Поскольку h > 1/2 при положительном
из отрезка [0 ; 1/2] ).
Поскольку h > 1/2 при положительном ![]() , то очевидно, что медиана G(x)
равна
, то очевидно, что медиана G(x)
равна ![]() , в
то время как медиана F(x) равна 1/2 . Значит, при
, в
то время как медиана F(x) равна 1/2 . Значит, при ![]() = 1/2 медианы совпадают, при всех
иных положительных
= 1/2 медианы совпадают, при всех
иных положительных ![]() - различны. При
- различны. При ![]() = 0 медианой G(x)
является любая точка из отрезка [0 ; 1].
= 0 медианой G(x)
является любая точка из отрезка [0 ; 1].
Легко подсчитать, что в условиях примера 4 параметры предельного распределения имеют вид
b2
= ![]() (1-
(1- ![]() )-1 / 4 , g2 =
(1- 2
)-1 / 4 , g2 =
(1- 2![]() ) / 4
.
) / 4
.
Следовательно, распределение нормированной и центрированной статистики Вилкоксона будет асимптотически нормальным с математическим ожиданием 0 и дисперсией
D(T)
= 3 [(n-1) ![]() (1-
(1- ![]() )-1 + (m-1) (1-2
)-1 + (m-1) (1-2![]() ) + 1] (m+n+1) - 1 .
) + 1] (m+n+1) - 1 .
Проанализируем
величину D(T) в зависимости от параметра ![]() и объемов выборок m и n. При
достаточно больших m и n
и объемов выборок m и n. При
достаточно больших m и n
D(T)
= 3 w ![]() (1
-
(1
- ![]() )-1 + 3
(1 - w) (1 - 2
)-1 + 3
(1 - w) (1 - 2 ![]() ) ,
) ,
с
точностью до величин порядка (m+n)-1 , где w= n/(m+n). Значит, D(T) - линейная
функция от w, а потому достигает экстремальных значений на границах интервала
изменения w, т.е. при w = 0 и w = 1. Легко видеть, что при ![]() (1-
(1-![]() )-1 <1-2
)-1 <1-2![]() минимум равен
3
минимум равен
3![]() (1-
(1-![]() )-1 (при w =
1), а максимум равен 3(1 - 2
)-1 (при w =
1), а максимум равен 3(1 - 2![]() ) (при w = 0). В случае
) (при w = 0). В случае ![]() (1-
(1-![]() )-1 >1-2
)-1 >1-2![]() максимум равен
3
максимум равен
3![]() (1-
(1-![]() )-1 (при w =
1), а минимум равен 3(1 - 2
)-1 (при w =
1), а минимум равен 3(1 - 2![]() ) (при w = 0). Если же
) (при w = 0). Если же ![]() (1-
(1-![]() )-1 =1-2
)-1 =1-2![]() (это равенство
справедливо при
(это равенство
справедливо при ![]() =
=![]() 0
= 1 - 2-1/2 = 0,293), то D(T)=3 (21/2-1)=1,2426... при всех w из отрезка [0;
1].
0
= 1 - 2-1/2 = 0,293), то D(T)=3 (21/2-1)=1,2426... при всех w из отрезка [0;
1].
Первый
из описанных выше случаев имеет быть при ![]() <
< ![]() 0
, при этом минимум D(T) возрастает от 0 (при
0
, при этом минимум D(T) возрастает от 0 (при ![]() =0, w=1 - предельный случай) до
3(21/2 - 1) (при
=0, w=1 - предельный случай) до
3(21/2 - 1) (при ![]() =
=![]() 0
, w - любом), а максимум уменьшается от 3 (при
0
, w - любом), а максимум уменьшается от 3 (при ![]() =0, w=0 - предельный случай) до 3
(21/2 - 1) (при
=0, w=0 - предельный случай) до 3
(21/2 - 1) (при ![]() =
=![]() 0
, w - любом). Второй случай относится к
0
, w - любом). Второй случай относится к ![]() из интервала (
из интервала (![]() 0 ; 1/2]. При этом
минимум убывает от приведенного выше значения для
0 ; 1/2]. При этом
минимум убывает от приведенного выше значения для ![]() =
=![]() 0 до 0 (при
0 до 0 (при ![]() =1/2 , w=0 - предельный
случай) , а максимум возрастает от того же значения при
=1/2 , w=0 - предельный
случай) , а максимум возрастает от того же значения при ![]() =
=![]() 0
до 3 (при
0
до 3 (при ![]() =1/2
, w=0).
=1/2
, w=0).
Таким
образом, D(T) может принимать все значения из интервала (0 ; 3) в зависимости
от значений ![]() и
w. Если D(T) < 1, то при применении критерия Вилкоксона к выборкам с
рассматриваемыми функциями распределения гипотеза однородности (2) будет
приниматься чаще (при соответствующих значениях
и
w. Если D(T) < 1, то при применении критерия Вилкоксона к выборкам с
рассматриваемыми функциями распределения гипотеза однородности (2) будет
приниматься чаще (при соответствующих значениях ![]() и w - с вероятностью, сколь
угодно близкой к 1), чем если бы она самом деле была верна. Если 1<D(T)<3,
то гипотеза (2) также принимается достаточно часто. Так, если уровень
значимости критерия Вилкоксона равен 0,05, то (асимптотическая) критическая
область этого критерия, как показано выше, имеет вид T: . Если -
самый плохой случай - D(T)=3, то гипотеза (2) принимается с вероятностью
0,7422.
и w - с вероятностью, сколь
угодно близкой к 1), чем если бы она самом деле была верна. Если 1<D(T)<3,
то гипотеза (2) также принимается достаточно часто. Так, если уровень
значимости критерия Вилкоксона равен 0,05, то (асимптотическая) критическая
область этого критерия, как показано выше, имеет вид T: . Если -
самый плохой случай - D(T)=3, то гипотеза (2) принимается с вероятностью
0,7422.
Гипотеза сдвига. При проверке гипотезы однородности мы рассмотрели различные виды нулевых и альтернативных гипотез - гипотезу (2) и ее отрицание в качестве альтернативы, гипотезу (6) и ее отрицание, гипотезы о равенстве или различии медиан. В теоретических работах по математической статистике часто рассматривают гипотезу сдвига, в которой альтернативой гипотезе (2) является гипотеза
H1: F(x) = G(x + r) (12)
при всех x и некотором сдвиге r, отличным от 0. Если верна альтернативная гипотеза H1, то вероятность P(X < Y) отлична от 1/2, а потому при альтернативе (12) критерий Вилкоксона является состоятельным.
В некоторых прикладных постановках гипотеза (12) представляется естественной. Например, если одним и тем же прибором проводятся две серии измерений двух значений некоторой величины (физической, химической и т.п.). При этом функция распределения G(x) описывает погрешности измерения одного значения, а G(x+r) - другого. Вопреки распространенному заблуждению, хорошо известно, что распределение погрешностей измерений, как правило, не является нормальным - см. об этом начало главы. Однако при анализе конкретных экономических данных как правило, нет никаких оснований считать, что отсутствие однородности всегда выражается столь однозначным образом, как следует из формулы (12). Поэтому эконометрику для проверки однородности необходимо использовать статистические критерии, состоятельные против любого отклонения от гипотезы однородности (2).
Почему же математики так любят гипотезу сдвига (12)? Да потому, что она дает возможность доказывать глубокие математические результаты, например, об асимптотической оптимальности критериев. К сожалению, с точки зрения эконометрики это напоминает поиск ключей под фонарем, где светло, а не там, где они потеряны.
Отметим еще одно обстоятельство. Часто говорят (в соответствии с классическим подходом математической статистики), что нельзя проверять нулевые гипотезы без рассмотрения альтернативных. Однако при эконометрическом анализе данных зачастую полностью ясна формулировка той гипотезы, которую желательно проверить (например, гипотезы полной однородности - см. формулу (2)), в то время как формулировка альтернативной гипотезы не очевидна (то ли это гипотеза о неверности равенства (2) хотя бы для одного значения x, то ли это альтернатива (8), то ли - альтернатива сдвига (12), и т.д.). В таких случаях целесообразно "обернуть" задачу - исходя из статистического критерия найти альтернативы, относительно которых он состоятелен. Именно это и проделано в настоящей пункте для критерия Вилкоксона.
Подведем итоги рассмотрения критерия Вилкоксона.
1. Критерий Вилкоксона (Манна-Уитни) является одним из самых распространенных непараметрических ранговых критериев, используемых для проверки однородности двух выборок. Его значение не меняется при любом монотонном преобразовании шкалы измерения (т.е. он пригоден для эконометрического анализа данных, измеренных в порядковой шкале).
2. Распределение статистики критерия Вилкоксона определяется функциями распределения F(x) и G(x) и объемами m и n двух выборок. При больших объемах выборок распределение статистики Вилкоксона является асимптотически нормальным с параметрами, выписанными выше ( см. формулы (1), (3) и (5)).
3. При альтернативной гипотезе, когда функции распределения выборок F(x) и G(x) не совпадают, распределение статистики Вилкоксона зависит от величины a = P(X < Y). Если a отличается от 1/2, то мощность критерия Вилкоксона стремится к 1, и отличает нулевую гипотезу F = G от альтернативной. Если же a = 1/2, то это не всегда имеет место. В примере 2 приведены две различные функции распределения выборок F(x) и G(x) такие, что гипотеза однородности F = G при проверке с помощью критерия Вилкоксона будет приниматься чаще, чем если она на самом деле верна.
4. Следовательно, в случае общей альтернативы критерий Вилкоксона не является состоятельным, т.е. не всегда позволяет обнаружить различие функций распределения. Однако это не лишает его практической ценности, точно так же, как несостоятельность критериев типа хи-квадрат при проверке согласия, независимости или однородности не мешает отклонять нулевую гипотезу во многих практически важных случаях. Однако принятие нулевой гипотезы с помощью критерия Вилкоксона может означать не совпадение F и G, а лишь выполнение равенства a = 1/2.
5. Иногда утверждают, что с помощью критерия Вилкоксона можно проверять равенство медиан функций распределения F и G. Это не так. В примерах 3 и 4 указаны F и G с a = 1/2, но с различными медианами. Во многих случаях это различие нельзя обнаружить с помощью критерия Вилкоксона, как это показано при численном анализе асимптотической дисперсии в примере 4.
6. Указанные выше недостатки критерия Вилкоксона исчезают для специального вида альтернативы - т.н. "альтернативы сдвига" H1: F(x) = G(x + r). В этом частном случае при справедливости альтернативной гипотезы мощность стремится к 1, различие медиан также всегда обнаруживается. Однако альтернатива сдвига не всегда естественна. Ее целесообразно принять, если одним и тем же прибором проводятся две серии измерений двух значений некоторой величины (физической, химической и т.п.). При этом функция распределения G(x) описывает результаты измерений с погрешностями одного значения, а F(x) = G(x+r) - другого. Другими словами, меняется лишь измеряемое значение, а собственно распределение погрешностей - одно и то же, присущее используемому средству измерения (и обычно описанное в его техническом паспорте). Однако в большинстве эконометрических исследований нет никаких оснований считать, что при альтернативе функция распределения второй выборки лишь сдвигается, но не меняется каким-либо иным образом.
7. При всех своих недостатках критерий Вилкоксона прост в применении и часто позволяет обнаруживать различие групп (поскольку оно часто сводится к отличию a = P(X < Y) от 1/2 ). Приведенные здесь критические замечания не следует понимать как призыв к полному отказу от использования критерия Вилкоксона. Однако для проверки гипотезы однородности в случае альтернативы общего вида можно порекомендовать состоятельные критерии, в частности, рассматриваемые в следующем пункте критерии Смирнова и типа омега-квадрат (Лемана-Розенблатта).
8. В литературе по прикладным статистическим методам соседствуют два стиля изложения. Один из них исходит из формулировок нулевой и альтернативных гипотез (или описания набора гипотез, из которого надо выбрать наиболее адекватную), для проверки которых строятся те или иные критерии. При другом стиле изложения упор делается на алгоритмическое описание критериев для проверки тех или иных гипотез, а об альтернативах даже не упоминается.
Например, в литературе по математической статистике часто говорится, что для проверки нормальности используются критерии асимметрии и эксцесса (они описаны, например, в лучшем справочнике 1960-1980-х годов [8, табл. 4.7]). Однако эти критерии позволяют проверять некоторые соотношения между моментами распределения, но отнюдь не являются состоятельными критериями нормальности (не все отклонения от нормальности обнаруживают). Впрочем, для эконометрики эти критерии практического значения не имеют, поскольку заранее известно, что распределения конкретных экономических данных отличны от нормальных.
Так что недостатки критерия Вилкоксона не является исключением, мощность ряда иных популярных в математической статистике критериев заслуживает тщательного изучения, при этом заранее можно сказать, что зачастую они не позволяют проверять те гипотезы, с которыми традиционно связаны. При применении подобных критериев к анализу реальных данных необходимо тщательно взвешивать их достоинства и недостатки.
Состоятельные критерии проверки однородности для независимых выборок
В соответствии с эконометрической теорией естественно потребовать, чтобы рекомендуемый для массового использования в экономических и технико-экономических исследованиях критерий однородности был состоятельным. Напомним: это значит, что для любых отличных друг от друга функций распределения F(x) и G(x) (другими словами, при справедливости альтернативной гипотезы H1) вероятность отклонения гипотезы H0 должна стремиться к 1 при увеличении объемов выборок т и п. Из перечисленных выше в конце п.4 критериев состоятельными являются только критерии Смирнова и типа омега-квадрат.
Проведенное исследование мощности (методом статистических испытаний) первых четырех из перечисленных выше критериев (при различных вариантах функций распределения F(x) и G(x)) подтвердило преимущество критериев Смирнова и омега-квадрат и при объемах выборок 6-12.
Критерий Смирнова однородности двух выборок. Он предложен членом-корреспондентом АН СССР Н.В. Смирновым в 1939 г. (см. справочник [8]). Единственное ограничение - функции распределения F(x) и G(x) должны быть непрерывными. Напомним, что согласно Л.Н. Большеву и Н.В. Смирнову [8] значение эмпирической функции распределения в точке х равно доле результатов наблюдений в выборке, меньших х. Критерий Смирнова основан на использовании эмпирических функций распределения Fm(x) и Gn(x), построенных по первой и второй выборкам соответственно. Значение статистики Смирнова
![]()
сравнивают с соответствующим критическим значением (см., например, [8]) и по результатам сравнения принимают или отклоняют гипотезу Н0 о совпадении (однородности) функций распределения. Практически значение статистики Dm,п рекомендуется согласно монографии [8] вычислять по формулам
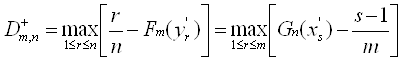 ,
,
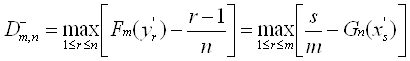 ,
,
![]() ,
,
где x'1<x'2<…<x'm - элементы первой выборки x1,x2,…,xm , переставленные в порядке возрастания, а y'1<y'2<…<y'n - элементы второй выборки y1,y2,…,yn , также переставленные в порядке возрастания.
Разработаны
алгоритмы и программы для ЭВМ, позволяющие рассчитывать точные распределения,
процентные точки и достигаемый уровень значимости для двухвыборочной статистики
Смирнова ![]() ,
разработаны подробные таблицы (см., например, методику [15], содержащую тексты
программ и подробные таблицы).
,
разработаны подробные таблицы (см., например, методику [15], содержащую тексты
программ и подробные таблицы).
Однако у критерия Смирнова есть и недостатки. Его распределение сосредоточено в сравнительно небольшом числе точек, поэтому функция распределения растет большими скачками. В результате не удается выдержать заданный уровень значимости, реальный уровень значимости может в несколько раз отличаться от номинального (подробному обсуждению неклассического феномена существенного отличия реального уровня значимости от номинального посвящена работа [16]).
Критерий типа омега-квадрат (Лемана-Розенблатта). Статистика критерия типа омега-квадрат для проверки однородности двух независимых выборок имеет вид:
A = ![]() Fm(x) – Gn(x))2
dHm+n(x) ,
Fm(x) – Gn(x))2
dHm+n(x) ,![]()
где Hm+n(x) – эмпирическая функция распределения, построенная по объединенной выборке,
Hm+n(x) = ![]() Fm(x) +
Fm(x) + ![]() Gn(x) .
Gn(x) .
Статистика
A типа омега-квадрат была предложена Э. Леманом в 1951 г., изучена М.
Розенблаттом в 1952 г., а затем и другими исследователями. Она зависит лишь от
рангов элементов двух выборок в объединенной выборке. Пусть ![]() - первая выборка,
- первая выборка, ![]() -
соответствующий вариационный ряд,
-
соответствующий вариационный ряд, ![]() -вторая выборка,
-вторая выборка, ![]() - вариационный ряд,
соответствующий второй выборке. Поскольку функции распределения независимых
выборок непрерывны, то с вероятностью 1 все выборочные значения различны,
совпадения отсутствуют. Статистика А представляется в виде (см., например,
[8]):
- вариационный ряд,
соответствующий второй выборке. Поскольку функции распределения независимых
выборок непрерывны, то с вероятностью 1 все выборочные значения различны,
совпадения отсутствуют. Статистика А представляется в виде (см., например,
[8]):
![]()
где ri - ранг x'i и sj - ранг y'j в общем вариационном ряду, построенном по объединенной выборке.
Правила принятия решений при проверке однородности двух выборок на основе статистик Смирнова и типа омега-квадрат, т.е. таблицы критических значений в зависимости от уровней значимости и объемов значимости приведены, например, в таблицах [8].
Рекомендации по выбору критерия однородности. Для критерия типа омега-квадрат нет выраженного эффекта различия между номинальными и реальными уровнями значимости. Поэтому мы рекомендуем для проверки однородности функций распределения (гипотеза H0) применять статистику А типа омега-квадрат. Если методическое, табличное или программное обеспечение для статистики Лемана-Розенблатта отсутствует, рекомендуем использовать критерий Смирнова. Для проверки однородности математических ожиданий (гипотеза H'0) целесообразно применять критерий Крамера-Уэлча. По нашему мнению, статистики Стьюдента, Вилкоксона и др. допустимо использовать лишь в отдельных частных случаях, рассмотренных выше.
Некоторые соображения о внедрении современных методов прикладной статистики в практику технических и технико-экономических исследований. Даже из проведенного выше разбора лишь одной из типичных статистических задач - задачи проверки однородности двух выборок - можно сделать вывод о целесообразности широкого развертывания в организациях различных форм собственности работ по критическому анализу сложившейся в технических и технико-экономических исследованиях практики статистической обработки данных и по внедрению накопленного арсенала современных методов прикладной статистики. По нашему мнению, широкого внедрения заслуживают, в частности, методы многомерного статистического анализа, планирования эксперимента, статистики объектов нечисловой природы. Очевидно, рассматриваемые работы должны быть плановыми, организационно оформленными, проводиться мощными самостоятельными организациями и подразделениями. Целесообразно создание службы статистических консультаций в системе научно-исследовательских учреждений и вузов технического и технико-экономического профиля.
Методы проверки однородности для связанных выборок
Начнем с практического примера. Приведем письмо главного инженера подмосковного химического комбината (некоторые названия изменены).
"Директору Института высоких статистических технологий и эконометрики (Фамилия, имя, отчество)
Наш комбинат выпускает мастику по ГОСТ (следует номер) и является разработчиком указанного стандарта.
В результате исследовательских работ по подбору стандартного метода определения вязкости мастики на комбинате накоплен большой опыт сравнительных данных определения вязкости по двум методам:
- неразбавленной мастики - на нестандартном приборе фабрики им. Петрова;
- раствора мастики - на стандартном вискозиметре ВЗ-4.
Учитывая высокую компетентность сотрудников Вашего института, прошу Вас, в порядке оказания технической помощи нашему предприятию, поручить соответствующей лаборатории провести обработку представленной статистики современными эконометрическими методами и выдать заключение о наличии (или отсутствии) зависимости между указанными выше методами определения вязкости мастики. Ваш5е заключение необходимо для решения спорного вопроса о целесообразности вновь ввести в ГОСТ (следует номер) метода определения вязкости мастики по вискозиметру ВЗ-4, который, по мнению некоторых потребителей, был необоснованно исключен из этого ГОСТ по изменению № 1.
Заранее благодарю Вас за оказанную помощь.
Приложение: статистика на 3 листах.
Главный инженер (Подпись) (Фамилия, имя, отчество)"
Комментарий. Вязкость мастики - один из показателей качества мастики. Измерять этот показатель можно по-разному. И, как оказалось, разные способы измерения дают разные результаты. Ничего необычного в этом нет. Однако поставщику и потребителю следует согласовать способы измерения показателей качества. Иначе достаточно часто поставщик (производитель) будет утверждать, что он выполнил условия контракта, а потребитель заявлять, что нет. Такая конфликтная ситуация иногда называется арбитражной, поскольку для ее решения стороны могут обращаться в арбитражный суд. Простейший метод согласования способов измерения показателей состоит в том, чтобы выбрать один из них и внести в государственный стандарт, который тем самым будет содержать не только описание продукции, перечень ее показателей качества и требований к ним, но и способы измерения этих показателей.
Заключение по статистическим данным, представленным химическим комбинатом. Для каждой из 213 партий мастики представлены два числа - результат измерения вязкости на нестандартном приборе фабрики им. Петрова и результат измерения вязкости на стандартном вискозиметре ВЗ-4. Требуется установить, дают ли два указанных метода сходные результаты. Если они дают сходные результаты, то нет необходимости вводить в соответствующий ГОСТ указание о методе определения вязкости. Если же методы дают существенно различные результаты, то подобное указание ввести необходимо.
Для применения эконометрических методов в
рассматриваемой задаче необходимо описать вероятностную модель. Считаем, что
статистические данные имеют вид ![]() где xi -результат
измерения на нестандартном приборе фабрики им. Петрова в i-ой партии, а yi - результат
измерения вязкости на стандартном вискозиметре ВЗ-4 в той же i-ой партии. Пусть ai - истинное
значение показателя качества в i-ой партии. Естественно считать, что указанные выше
случайные вектора независимы в совокупности. При этом они не являются одинаково
распределенными, поскольку отличаются истинными значениями показателей качества
ai. Принимаем, что при каждом i случайные величины xi - ai
и yi - ai независимы и одинаково распределены. Это
условие и означает однородность в связанных выборках. Параметры связи -
величины ai . Их наличие не позволяет объединить первые
координаты в одну выборку, вторую - во вторую, как делалось в случае проверки
однородности двух независимых выборок.
где xi -результат
измерения на нестандартном приборе фабрики им. Петрова в i-ой партии, а yi - результат
измерения вязкости на стандартном вискозиметре ВЗ-4 в той же i-ой партии. Пусть ai - истинное
значение показателя качества в i-ой партии. Естественно считать, что указанные выше
случайные вектора независимы в совокупности. При этом они не являются одинаково
распределенными, поскольку отличаются истинными значениями показателей качества
ai. Принимаем, что при каждом i случайные величины xi - ai
и yi - ai независимы и одинаково распределены. Это
условие и означает однородность в связанных выборках. Параметры связи -
величины ai . Их наличие не позволяет объединить первые
координаты в одну выборку, вторую - во вторую, как делалось в случае проверки
однородности двух независимых выборок.
В предположении непрерывности функций распределения из условия однородности в связанных выборках вытекает, что
![]()
Рассмотрим случайные величины ![]() Из последнего соотношения
вытекает, что при справедливости гипотезы однородности для связанных выборок
эти случайные величины имеют нулевые медианы. Другими словами, проверка того,
что метода измерения вязкости дают схожие результаты, эквивалентна проверке
равенства 0 медиан величин Zi.
Из последнего соотношения
вытекает, что при справедливости гипотезы однородности для связанных выборок
эти случайные величины имеют нулевые медианы. Другими словами, проверка того,
что метода измерения вязкости дают схожие результаты, эквивалентна проверке
равенства 0 медиан величин Zi.
Для проверки гипотезы о том, что медианы величин Zi
нулевые, применим широко известный критерий знаков (см., например, справочник
[8, с.89-91]). Согласно этому критерию необходимо подсчитать, в скольких
партиях ![]() и
в скольких
и
в скольких ![]() .
Для представленных химическим комбинатом данных
.
Для представленных химическим комбинатом данных ![]() в 187 случаях из 213 и
в 187 случаях из 213 и ![]() в 26 случаях
из 213.
в 26 случаях
из 213.
Если рассматриваемая гипотеза верна, то число W осуществлений события ![]() имеет биномиальное распределение
с параметрами p = 1/2 и n = 213. Математическое ожидание М(W)=106,5, а среднее
квадратическое отклонение
имеет биномиальное распределение
с параметрами p = 1/2 и n = 213. Математическое ожидание М(W)=106,5, а среднее
квадратическое отклонение ![]() Следовательно, интервал
Следовательно, интервал ![]() - это интервал
84<W<129. Найденное по данным химического комбината
значение W=187 лежит далеко вне этого интервала. Поэтому
рассматриваемую гипотезу необходимо отвергнуть (на любом используемом в
прикладных работах уровне значимости, в частности, на уровне значимости 1%).
- это интервал
84<W<129. Найденное по данным химического комбината
значение W=187 лежит далеко вне этого интервала. Поэтому
рассматриваемую гипотезу необходимо отвергнуть (на любом используемом в
прикладных работах уровне значимости, в частности, на уровне значимости 1%).
Таким образом, статистический анализ показывает, что два метода дают существенно различные результаты - по прибору фабрики им. Петрова результаты измерений, как правило, меньше, чем по вискозиметру ВЗ-4. Это означает, что в соответствующий ГОСТ целесообразно ввести указание на метод определения вязкости.
Система вероятностных моделей при проверке гипотезы однородности для связанных выборок. Как и в случае проверки однородности для независимых выборок, система вероятностных моделей состоит из трех уровней. Наиболее простая модель - на уровне однородности альтернативного признака - уже рассмотрена. Она сводится к проверке гипотезы для биномиального распределения:
![]()
Речь идет о "критерии знаков". При
справедливости гипотезы однородности число W осуществлений события ![]() имеет биномиальное распределение
с вероятностью успеха p = 1/2 и числом испытаний n. Альтернативная гипотеза
состоит в том, что вероятность успеха отличается от 1/2:
имеет биномиальное распределение
с вероятностью успеха p = 1/2 и числом испытаний n. Альтернативная гипотеза
состоит в том, что вероятность успеха отличается от 1/2:
![]()
Гипотезу p = 1/2 можно проверять как непосредственно с помощью биномиального распределения (используя таблицы или программное обеспечение), так и опираясь на теорему Муавра-Лапласа. Согласно этой теореме
![]()
при всех х, где Ф(х) - функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. Из теоремы Муавра-Лапласа вытекает правило принятия решений на уровне значимости 5%: если
![]()
то гипотезу однородности связанных выборок принимают, в противном случае отклоняют. Как обычно, при желании использовать другой уровень значимости применяют в качестве критического значения иной квантиль нормального распределения. Использование предельных теорем допустимо при достаточно больших объемах выборки. По поводу придания точного смысла термину "достаточно большой" продолжаются дискуссии. Обычно считается, что несколько десятков (два-три десятка) - это уже "достаточно много". Более правильно сказать, что ответ зависит от задачи, от ее сложности и практической значимости.
Второй уровень моделей проверки однородности связанных выборок - это уровень проверки однородности характеристик, прежде всего однородности математических ожиданий. Исходные данные - количественные результаты измерений (наблюдений, испытаний, анализов, опытов) двух признаков хj и уj , j = 1,2,…,n, а непосредственно анализируются их разности Zj = хj - уj , j = 1,2,…,n. Предполагается, что эти разности независимы в совокупности и одинаково распределены, однако функция распределения неизвестна эконометрику. Необходимо проверить непараметрическую гипотезу
![]()
Альтернативная гипотеза также является непараметрической и имеет вид:
![]()
![]()
Как и в случае проверки гипотезы согласованности для независимых выборок с помощью критерия Крамера-Уэлча, в рассматриваемой ситуации естественно использовать статистику
![]()
где
![]()
среднее арифметическое разностей, а
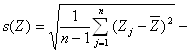
выборочное среднее квадратическое отклонение. Из центральной Предельной Теоремы теории вероятностей и теорем о наследовании сходимости, полученных в монографии [11], вытекает, что
![]()
при всех х, где Ф(х) - функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. Отсюда вытекает правило принятия решений на уровне значимости 5%: если
![]()
то гипотезу однородности математических ожиданий связанных выборок принимают, в противном случае отклоняют. Как обычно, при желании использовать другой уровень значимости применяют в качестве критического значения иной квантиль нормального распределения. Повторим, что использование предельных теорем допустимо при достаточно больших объемах выборки.
Третий уровень моделей проверки однородности связанных выборок - это уровень проверки однородности (совпадения) функций распределения. Необходимо проверить непараметрическую гипотезу наиболее всеохватного вида:
![]()
где
![]()
При этом предполагается, что все участвующие в вероятностной модели случайные величины независимы (в совокупности) между собой.
Отметим одно важное свойство функции распределения случайной величины Z. Если случайные величины х и у независимы и одинаково распределены, то для H(x)=P(Z<x) выполнено, как нетрудно видеть, соотношение
H(-x)=1-H(x).
Это соотношение означает симметрию функции распределения относительно 0. Плотность такой функции распределения является четной функцией, ее значения в точках х и (-х) совпадают.
Какого типа отклонения от гипотезы симметрии можно ожидать при альтернативных гипотезах?
Как и в случае проверки однородности независимых выборок, в зависимости от вида альтернативной гипотезы выделяют два подуровня моделей. Рассмотрим сначала альтернативу сдвига
![]()
В этом случае распределение Z при альтернативе отличается сдвигом от симметричного относительно 0. Для проверки гипотезы однородности может быть использован критерий знаковых рангов, разработанный Вилкоксоном (см., например, справочник [9, с.46-53]).
Он строится следующим образом. Пусть R(Zj) является рангом |Zj| в ранжировке от меньшего к большему абсолютных значений разностей |Z1|, |Z2|,…,|Zn|, j=1,2,…,n. Положим для j=1,2,…,n
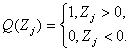
Статистика критерия знаковых рангов имеет вид
![]()
Таким образом, нужно просуммировать ранги положительных разностей в вариационном ряду, построенном стандартным образом по абсолютным величинам всех разностей.
Для практического использования статистики критерия знаковых рангов Вилкоксона либо обращаются к соответствующим таблицам и программному обеспечению, либо применяют асимптотические соотношения. При выполнении нулевой гипотезы статистика
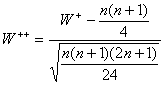
имеет
асимптотическое (при ![]() ) стандартное нормальное
распределение с математическим ожиданием 0 и дисперсией 1. Следовательно,
правило принятия решений на уровне значимости 5%: имеет обычный вид если
) стандартное нормальное
распределение с математическим ожиданием 0 и дисперсией 1. Следовательно,
правило принятия решений на уровне значимости 5%: имеет обычный вид если
![]()
то гипотезу однородности связанных выборок по критерию знаковых рангов Вилкоксона принимают, в противном случае отклоняют. Как обычно, при желании использовать другой уровень значимости применяют в качестве критического значения иной квантиль нормального распределения. Повторим еще раз, что использование предельных теорем допустимо при достаточно больших объемах выборки.
Альтернативная гипотеза общего вида записывается как
![]()
при некотором х0 . Таким образом, проверке подлежит гипотеза симметрии относительно 0, которую можно переписать в виде
H(x) + H(-x) -1 = 0 .
Для построенной по выборке Zj = хj - уj , j = 1,2,…,n, эмпирической функции распределения Hn(x) последнее соотношение выполнено лишь приближенно:
![]()
Как измерять отличие от 0? По тем же соображениям, что и в предыдущем пункте, целесообразно использовать статистику типа омега-квадрат. Соответствующий критерий был предложен в работе [17]. Он имеет вид
![]()
В работе [17] найдено предельное распределение этой статистики:
![]()
В табл.1 приведены критические значения статистики типа омега-квадрат для проверки симметрии распределения (и тем самым для проверки однородности связанных выборок), соответствующие наиболее распространенным значениям уровней значимости (расчеты проведены Г.В. Мартыновым).
Табл.1.
Критические значения статистики ![]() для проверки симметрии
распределения
для проверки симметрии
распределения
|
Значение
функции распределения |
Уровень
значимости |
Критическое
значение х статистики |
| 0,90 | 0,10 | 1,20 |
| 0,95 | 0,05 | 1,66 |
| 0,99 | 0,01 | 2,80 |
Как
следует из табл.1, правило принятия решений при проверке однородности связанных
выборок в наиболее общей постановке и при уровне значимости 5% формулируется
так. Вычислить статистику ![]() . Если
. Если ![]() <1,66, то принять гипотезу
однородности. В противном случае - отвергнуть.
<1,66, то принять гипотезу
однородности. В противном случае - отвергнуть.
Пример. Пусть величины Zj , j=1,2,…,20, таковы:
20, 18, (-2), 34, 25, (-17), 24, 42, 16, 26, 13, (-23), 35, 21, 19, 8, 27, 11, (-5), 7.
Соответствующий
вариационный ряд ![]() имеет вид:
имеет вид:
(-23)<(-17)<(-5)<(-2)<7<8<11<13<16<18<19<20<21<24<25<26<27<34<35<42.
Для
расчета значения статистики ![]() построим табл.2 из 7 столбцов и
20 строк, не считая заголовков столбцов (сказуемого таблицы). В первом столбце
указаны номера (ранги) членов вариационного ряда, во втором - сами эти члены, в
третьем - значения эмпирической функции распределения при значениях аргумента,
совпадающих с членами вариационного ряда. В следующем столбце приведены члены
вариационного ряда с обратным знаком, а затем указываются соответствующие
значения эмпирической функции распределения. Например, поскольку минимальное
наблюдаемое значение равно (-23), то Hn(x)=0 при x<-23, а потому
для членов вариационного ряда с 14-го по 20-й в пятом столбце стоит 0. В
качестве другого примера рассмотрим минимальный член вариационного ряда, т.е.
(-23). Меняя знак, получаем 23. Это число стоит между 13-м и 14-м членами
вариационного ряда, 21<23<24. На этом интервале эмпирическая функция
распределения совпадает со своим значением в левом конце, поэтому следует
записать в пятом столбце значение 0,65. Остальные ячейки пятого столбца
заполняются аналогично. На основе третьего и пятого столбцов элементарно
заполняется шестой столбец, а затем и седьмой. Остается найти сумму значенийб
стоящих в седьмом столбце. Подобная таблица удобна как для ручного счета, так и
при использовании электронных таблиц типа Excel.
построим табл.2 из 7 столбцов и
20 строк, не считая заголовков столбцов (сказуемого таблицы). В первом столбце
указаны номера (ранги) членов вариационного ряда, во втором - сами эти члены, в
третьем - значения эмпирической функции распределения при значениях аргумента,
совпадающих с членами вариационного ряда. В следующем столбце приведены члены
вариационного ряда с обратным знаком, а затем указываются соответствующие
значения эмпирической функции распределения. Например, поскольку минимальное
наблюдаемое значение равно (-23), то Hn(x)=0 при x<-23, а потому
для членов вариационного ряда с 14-го по 20-й в пятом столбце стоит 0. В
качестве другого примера рассмотрим минимальный член вариационного ряда, т.е.
(-23). Меняя знак, получаем 23. Это число стоит между 13-м и 14-м членами
вариационного ряда, 21<23<24. На этом интервале эмпирическая функция
распределения совпадает со своим значением в левом конце, поэтому следует
записать в пятом столбце значение 0,65. Остальные ячейки пятого столбца
заполняются аналогично. На основе третьего и пятого столбцов элементарно
заполняется шестой столбец, а затем и седьмой. Остается найти сумму значенийб
стоящих в седьмом столбце. Подобная таблица удобна как для ручного счета, так и
при использовании электронных таблиц типа Excel.
Табл.2.
Расчет значения статистики ![]() для проверки симметрии
распределения
для проверки симметрии
распределения
| j | Z(j) |
Hn(Z(j)) |
-Z(j) |
Hn(-Z(j)) |
Hn(Z(j))+ Hn(-Z(j))-1 |
(Hn(Z(j))+ Hn(-Z(j))-1)2 |
| 1 | -23 | 0,05 | 23 | 0,65 | -0,30 | 0,09 |
| 2 | -17 | 0,10 | 17 | 0,45 | -0,45 | 0,2025 |
| 3 | -5 | 0,15 | 5 | 0,20 | -0,65 | 0,4225 |
| 4 | -2 | 0,20 | 2 | 0,20 | -0,60 | 0,36 |
| 5 | 7 | 0,25 | -7 | 0,10 | -0,65 | 0,4225 |
| 6 | 8 | 0,30 | -8 | 0,10 | -0,60 | 0,36 |
| 7 | 11 | 0.35 | -11 | 0,10 | -0,55 | 0,3025 |
| 8 | 13 | 0,40 | -13 | 0,10 | -0,50 | 0,25 |
| 9 | 16 | 0,45 | -16 | 0,10 | -0,45 | 0,2025 |
| 10 | 18 | 0,50 | -18 | 0,05 | -0,45 | 0,2025 |
| 11 | 19 | 0,55 | -19 | 0,05 | -0,40 | 0,16 |
| 12 | 20 | 0,60 | -20 | 0,05 | -0,35 | 0,1225 |
| 13 | 21 | 0,65 | -21 | 0,05 | -0,30 | 0,09 |
| 14 | 24 | 0,70 | -24 | 0 | -0,30 | 0,09 |
| 15 | 25 | 0,75 | -25 | 0 | -0,25 | 0,0625 |
| 16 | 26 | 0,80 | -26 | 0 | -0,20 | 0,04 |
| 17 | 27 | 0,85 | -27 | 0 | -0,15 | 0,0225 |
| 18 | 34 | 0,90 | -34 | 0 | -0,10 | 0,01 |
| 19 | 35 | 0,95 | -35 | 0 | -0,05 | 0,0025 |
| 20 | 42 | 1,00 | -42 | 0 | 0 | 0 |
Результаты
расчетов (суммирование значений по седьмому столбцу табл.2) показывают, что
значение статистики ![]() =3,055. В соответствии с табл.1
это означает, что на любом используемом в прикладных эконометрических
исследованиях уровнях значимости отклоняется гипотеза симметрии распределения
относительно 0 (а потому и гипотеза однородности в связанных выборках).
=3,055. В соответствии с табл.1
это означает, что на любом используемом в прикладных эконометрических
исследованиях уровнях значимости отклоняется гипотеза симметрии распределения
относительно 0 (а потому и гипотеза однородности в связанных выборках).
В настоящей главе затронута лишь небольшая часть непараметрических методов анализа числовых эконометрических данных. Обратим вн6имание на непараметрические оценки плотности, которые используются для описания данных, проверки однородности, в задачах восстановления зависимостей и других областях эконометрики. Эконометрические оценки плотности в общем виде рассмотрены в главе 8.
Цитированная литература
1. Новицкий П.В., Зограф И.А. Оценка погрешностей результатов измерений. - Л.: Энергоатомиздат, 1985. - 248 с.
2. Новицкий П.В. Основы информационной теории измерительных устройств. -Л.: энергия, 1968. - 248 с.
3. Боровков А.А. Теория вероятностей. - М.: Наука, 1976. - 352 с.
4. Петров В.В. Суммы независимых случайных величин. - М.: Наука, 1972. - 416 с.
5. Золотарев В.М. Современная теория суммирования независимых случайных величин. - М.: Наука, 1986. - 416 с.
6. Егорова Л.А., Харитонов Ю.С., Соколовская Л.В.//Заводская лаборатория. - 1976. Т.42, №10. С. 1237.
7. Артемьев Б.Г., Голубов С.М. Справочное пособие для работников метрологических служб.- М.: Изд-во стандартов, 1982. - 280 с.
8. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. – М.: Наука, 1983. - 416 с.
9. Холлендер М., Вульф Д. Непараметрические методы статистики. – М.: Финансы и статистика, 1983. - 518 с.
10. Боровков А.А. Математическая статистика. – М.: Наука, 1984. - 472 с.
11. Îðëîâ À.È. Óñòîé÷èâîñòü â ñîöèàëüíî-ýêîíîìè÷åñêèõ ìîäåëÿõ. - Ì.:Íàóêà,1979. – 296 ñ.
12. Крамер Г. Математические методы статистики / Пер. с англ. / 2-е изд. - М.: Мир, 1975. – 648 с.
13. Гаек Я., Шидак 3. Теория ранговых критериев / Пер. с англ. - М.: Наука, 1971. – 376 с.
14. Смолянский М.Л. Таблицы неопределенных интегралов. - М.: ГИФМЛ, 1961. - 108 с.
15. Методика. Проверка однородности двух выборок параметров продукции при оценке ее технического уровня и качества. – М.: ВНИИ стандартизации, 1987. – 116 с.
16. Камень Ю.Э., Камень Я.Э., Орлов А.И. Реальные и номинальные уровни значимости в задачах проверки статистических гипотез / Заводская лаборатория. 1986. Т.52. № 12. С.55-57.
17. Орлов А.И. О проверке симметрии распределения. – Журнал «Теория вероятностей и ее применения». 1972. Т.17. No.2. С.372-377.