
Главная
Рефераты по зарубежной литературе
Рефераты по логике
Рефераты по маркетингу
Рефераты по международному публичному праву
Рефераты по международному частному праву
Рефераты по международным отношениям
Рефераты по культуре и искусству
Рефераты по менеджменту
Рефераты по металлургии
Рефераты по муниципальному праву
Рефераты по налогообложению
Рефераты по оккультизму и уфологии
Рефераты по педагогике
Рефераты по политологии
Рефераты по праву
Биографии
Рефераты по предпринимательству
Рефераты по психологии
Рефераты по радиоэлектронике
Рефераты по риторике
Рефераты по социологии
Рефераты по статистике
Рефераты по страхованию
Рефераты по строительству
Рефераты по схемотехнике
Рефераты по таможенной системе
Сочинения по литературе и русскому языку
Рефераты по теории государства и права
Рефераты по теории организации
Рефераты по теплотехнике
Рефераты по технологии
Рефераты по товароведению
Рефераты по транспорту
Рефераты по трудовому праву
Рефераты по туризму
Рефераты по уголовному праву и процессу
Рефераты по управлению
Курсовая работа: Статистические ряды распределения в изучении структуры рынка
Курсовая работа: Статистические ряды распределения в изучении структуры рынка
Федеральное агентство по образованию
Государственное образовательное учреждение высшего профессионального образования
Всероссийский заочный финансово-экономический институт
Кафедра Статистики
Курсовая работа
по дисциплине Статистика
на тему:
Статистические ряды распределения в изучении структуры рынка
Руководитель: Пуляшкин В.В.
Москва
2007
Введение
Статистические ряды распределения являются одним из наиболее важных элементов статистики. Они представляют собой составную часть метода статистических сводок и группировок, но, по сути, ни одно из статистических исследований невозможно произвести, не представив первоначально полученную в результате статистического наблюдения информацию в виде статистических рядов распределения. Первичные данные обрабатываются в целях получения обобщенных характеристик изучаемого явления по роду существенных признаков для дальнейшего осуществления анализа и прогнозирования; производится сводка и группировка; статистические данные оформляются с помощью рядов распределения в таблицы, в результате чего информация представляется в наглядном рационально изложенном виде, удобном для использования и дальнейшего исследования; строятся различного рода графики для наиболее наглядного восприятия и анализ информации. На основе статистических рядов распределения вычисляются основные величины статистических исследований: индексы, коэффициенты; абсолютные, относительные, средние величины и т.д., с помощью которых можно проводить прогнозирование, как конечный итог статистических исследований. Таким образом статистические ряды распределения являются базисным методом для любого статистического анализа. Понимание данного метода и навыки его использования необходимы для проведения статистических исследований.
В теоретической части курсовой работы рассмотрены следующие аспекты:
1) Понятие статистических рядов распределения, их виды;
2) Расчет средних величин, моды и медианы и представление рядов распределения графически;
Расчетная часть курсовой работы включает решение задачи по теме из варианта расчетного задания: Работа с таблицей «Выборочные данные торговых предприятий района: товарооборот и средние товарные запасы». Предметом исследования в работе будут служить так же торговые предприятия района (каждое предприятие, из которых, со своим товарооборотом). Работа содержит расчеты всех данных по ним, так же полное описание шагов действий для достижения конечного результата (вывода).
При написании курсовой работы использовались учебники курса, дополнительная литература, Интернет-ресурсы; при работе с табличными данными - персональный компьютер конфигурации:
Процессор – ADM Sempron 28000+S754
Память – DDR 512Mb PC3200 (DDR400)![]()
Жесткий диск – 120Gb 7200/8 Mb/SATA
Принтер – hp deskjet 3325, струйный
OC – Windows XP Professional
ППП – Microsoft Word 2002, Excel
1. Теоретическая часть
1) Понятие статистических рядов распределения и их виды
Результаты сводки и группировки материалов статистического наблюдения оформляются в виде статистических рядов распределения. Статистические ряды распределения представляют собой упорядоченное распределение единиц изучаемой совокупности на группы по группировочному (варьирующему) признаку. Они характеризуют состав изучаемого явления, позволяют судить об однородности совокупности, границах ее изменения, закономерностях развития наблюдаемого объекта. В зависимости от признака статистические ряды распределения делятся на следующие:
- атрибутивные (качественные);
- вариационные (количественные):
a) дискретные;
b) интервальные.
а) Атрибутивные ряды распределения
Атрибутивные ряды образуются по качественным признакам, которыми могут выступать занимаемая должность работников торговли, профессия, пол, образование и т.д. В правовой статистике - это виды преступлений (убийства, грабежи, разбои); занимаемая должность лиц, совершивших административные правонарушения; образование и т.д.
Пример атрибутивных рядов распределения:
Таблица 1. Распределение преступлений в г. Москве за сутки по видам
| Виды преступлений | Количество преступлений | |
| абсолютное | в % к итогу | |
| Убийства | 3 | 3,2 |
| Тяжкие телесные повреждения | 3 | 3,2 |
| Изнасилования | 1 | 1,1 |
| Разбои | 4 | 4,3 |
| Грабежи | 15 | 16,1 |
| Кражи | 52 | 56,0 |
| Изъятия наркотиков | 15 | 16,1 |
| Итого | 93 | 100 |
В данном примере группировочным признаком выступают виды преступлений. Данный ряд распределения является атрибутивным, поскольку варьирующий признак представлен не количественными, а качественными показателями. Наибольшее число правонарушений составляют кражи 56%; далее правонарушения распределяются поровну между грабежами и случаями изъятия наркотиков (16%) и убийствами и случаями нанесения тяжких телесных повреждений (3%); разбои составили 4.5%, и наименьшее число зарегистрированных правонарушений составили изнасилования -1%.
б) Вариационные ряды распределения
Вариационные ряды строятся на основе количественного группировочного признака. При этом вариационные ряды по способу построения бывают дискретными (прерывными) и интервальными (непрерывными).
Дискретный ряд
распределения - ряд, который основан на прерывной вариации признака, т.е. в
котором значение признака выражено целым числом (число раскрытых преступлений и
т.д.). Для построения дискретного ряда с небольшим числом вариантов
выписываются все встречающиеся варианты значений признака ![]() , а затем
подсчитывается частота повторения варианта
, а затем
подсчитывается частота повторения варианта ![]() . Ряд распределения принято оформлять в виде таблицы, состоящей
из двух колонок (или строк), в одной из которых представлены варианты, а в
другой - частоты.
. Ряд распределения принято оформлять в виде таблицы, состоящей
из двух колонок (или строк), в одной из которых представлены варианты, а в
другой - частоты.
Интервальный ряд распределения - ряд, базирующийся на непрерывно изменяющемся значении признака, имеющего любые количественные выражения, т.е. значение признаков таких рядах задается в виде интервала.
При наличии достаточно большого количества вариантов значений признака первичный ряд является труднообозримым, и непосредственное рассмотрение его не дает представления о распределении единиц по значению признака в совокупности. Поэтому первым шагом в упорядочении первичного ряда является его ранжирование – расположение всех вариантов в возрастающем (убывающем) порядке
Вариационные ряды состоят из двух элементов: вариант и частот.
Варианта - это отдельное значение варьируемого признака, которое он принимает в ряду распределения.
Частота - это численность отдельных вариант или каждой группы вариационного ряда. Частоты, выраженные в долях единицы или в процентах к итогу, называются частостями. Сумма частот составляет объем ряда распределения.
Для построения ряда распределения непрерывно изменяющихся признаков, либо дискретных, представленных в виде интервалов, необходимо установить оптимальное число интервалов, на которые следует разбить все единицы изучаемой совокупности.
2) Графическое изображение статистических данных
Статистический график – это чертеж, на котором статистические совокупности, характеризуемые определенными показателями, описываются с помощью условных геометрических образов или знаков. Представление данных таблиц в виде графика производит более сильное впечатление, чем цифры, позволяет лучше осмыслить результаты статистического наблюдения, правильно их истолковывать, значительно облегчает понимание статистического материала, делает его наглядным и доступным.
Значение графического метода в анализе и обобщении данных велико. Графическое изображение позволяет осуществить контроль достоверности статистических показателей, так как, представленные на графике, они более ярко показывают имеющиеся неточности, связанные либо с наличием ошибок наблюдения, либо с сущностью изучаемого явления. С помощью графического изображения возможны изучение закономерностей развития явления, установление существующих взаимосвязей. Простое сопоставление данных не всегда дает возможность уловить наличие причинных зависимостей, в то же время их графическое изображение способствует выявлению причинных связей, в особенности в случае установления первоначальных гипотез, подлежащих затем дальнейшей разработке. Графики также широко используются для изучения структуры явлений, их изменения во времени и размещения в пространстве. В них более выразительно проявляются сравнительные характеристики и отчетливо виды основные тенденции развития и взаимосвязи, присущие изучаемому явлению или процессу.
Таблица 2. Распределение студентов по возрасту
| Возраст студентов | Число студентов данного возраста |
| 17 | 1 |
| 18 | 4 |
| 19 | 2 |
| 20 | 2 |
| 21 | 5 |
| Итого | 14 |
График 1
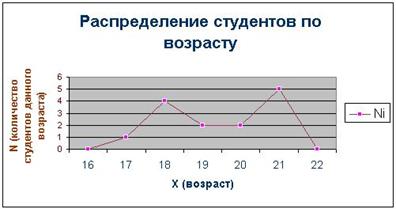
Расчет показателей вариации.
Вариация – это различие в значениях какого-либо признака у разных единиц данной совокупности в один и тот же период или момент времени. Исследование вариации в статистике имеет большое значение, помогает познать сущность изучаемого явления. Показатели вариации характеризуют колеблемость отдельных значений вариант около средних величин. Показатели вариации определяют различия индивидуальных значений признака внутри изучаемой совокупности. Существует несколько видов показателей вариации:
а) Размах вариации R представляет собой разность между максимальным и минимальным значениями признака:
R = Xmax – Xmin
Размах вариации показывает лишь крайние отклонения признака и не отражает отклонений всех вариантов в ряду.
б) Среднее линейное отклонение
(7)  - невзвешенное;
- невзвешенное;
(8) 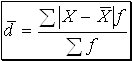 - взвешенное,
- взвешенное,
где: Х - варианты;
`Х - средняя величина;
n - число признаков;
f - частоты.
Линейное отклонение учитывает различия всех единиц изучаемой совокупности.
в) Дисперсия - показатель вариации, выражающий средний квадрат отклонений вариант от средних величин в зависимости от образующего вариационного фактора.
(9) 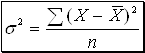 - невзвешенная;
- невзвешенная;
(10) 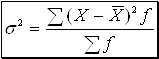 - взвешенная.
- взвешенная.
Показатель дисперсии более объективно отражает меру вариации на практике.
г) Среднее квадратическое отклонение
(11) 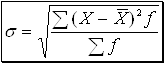 - взвешенное;
- взвешенное;
(12) 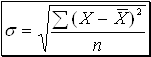 - невзвешенное.
- невзвешенное.
Среднее квадратическое отклонение является показателем надежности средней: чем меньше среднее квадратическое отклонение, тем лучше средняя арифметическая отражает собой всю статистическую совокупность.
д) Показатель вариации.
(13) 
Показатель вариации отражает тенденцию развития явления, т.e. действие главных факторов. Показатель вариации выражается в % или коэффициентах.
Расчет моды и медианы.
Особым видом средних величин являются структурные средние. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся мода и медиана.
Мода - это величина признака (варианта), который наиболее часто встречается в данной совокупности, т.e. это варианта, имеющая наибольшую частоту.
В интервальном ряду распределения мода находится по следующей формуле:
(4)  ,
,
где:![]() минимальная
граница модального интервала;
минимальная
граница модального интервала;
![]() - величина модального интервала;
- величина модального интервала;
![]() {частоты модального интервала,
предшествующего и следующего за ним
{частоты модального интервала,
предшествующего и следующего за ним
Модальный интервал определяется по наибольшей частоте. Мода широко используется в статистической практике при изучении покупательского спроса, регистрации цен и т.д.
Медиана - варианта, находящаяся в середине ряда распределения.
Медиана делит ряд на две равные (по числу единиц) части – со значениями признака меньше медианы и со значениями признака больше медианы.
В случае если вариационный ряд имеет число значений вариант четное, то расчет медианы производится по следующей формуле:
(5) 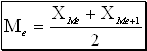 ,
,
где ![]() - варианты,
находящиеся в середине ряда
- варианты,
находящиеся в середине ряда
В интервальном ряду распределения медиана рассчитывается следующим образом:
(6)  ,
,
где:![]() - нижняя граница
медианного интервала;
- нижняя граница
медианного интервала;
![]() - величина медианного интервала;
- величина медианного интервала;
![]() - полусумма частот ряда;
- полусумма частот ряда;
![]() - сумма накопленных частот,
предшествующих медианному интервалу;
- сумма накопленных частот,
предшествующих медианному интервалу;
![]() - частота медианного интервала.
- частота медианного интервала.
Структурные средние
величины (мода и медиана) имеют довольно большое значение в статистике и
широкое применение. Мода является именно тем числом, которое в действительности
встречается наиболее часто. Медиана имеет важные свойства для анализа явлений:
она обнаруживает типичные черты индивидуальных признаков явления, и, вместе с
тем, учитывает влияние крайних значений совокупности. Медиана находит
практическое применение в маркетинговой деятельности вследствие особого
свойства – сумма абсолютных отклонений чисел ряда от медианы есть величина
наименьшая: ![]()
2. Расчетная часть
По результатам 20%-ного выборочного обследования торговых предприятий района, проведенного на основе случайной бесповторной выборки, получены следующие данные за отчетный месяц (тыс. руб.)
Таблица 1. Исходные данные
| № п\п | Товарооборот | Средние товарные запасы | № п\п | Товарооборот | Средние товарные запасы |
| 1 | 614 | 256 | 16 | 653 | 254 |
| 2 | 396 | 168 | 17 | 704 | 251 |
| 3 | 681 | 252 | 18 | 759 | 293 |
| 4 | 543 | 221 | 19 | 384 | 158 |
| 5 | 540 | 210 | 20 | 492 | 188 |
| 6 | 706 | 278 | 21 | 610 | 237 |
| 7 | 576 | 214 | 22 | 591 | 239 |
| 8 | 537 | 169 | 23 | 550 | 191 |
| 9 | 744 | 288 | 24 | 603 | 236 |
| 10 | 523 | 213 | 25 | 528 | 215 |
| 11 | 375 | 150 | 26 | 795 | 301 |
| 12 | 429 | 208 | 27 | 611 | 228 |
| 13 | 552 | 218 | 28 | 589 | 230 |
| 14 | 642 | 227 | 29 | 627 | 263 |
| 15 | 618 | 238 | 30 | 698 | 246 |
Цель статистического исследования - анализ совокупности предприятий по признакам Товарооборот и Средние товарные запасы, включая:
· изучение структуры совокупности по признаку Товарооборота;
· выявление наличия корреляционной связи между признаками Товарооборота и Средними товарными запасами предприятий, установление направления связи и оценка её тесноты;
· применение выборочного метода для определения статистических характеристик генеральной совокупности фирм.
Задание 1
По исходным данным (табл. 1) необходимо выполнить следующее:
1. Построить статистический ряд распределения предприятий по товарообороту, образовав пять групп с равными интервалами.
2. Графическим методом и путем расчетов определить значения моды и медианы полученного ряда распределения.
3. Рассчитать характеристики ряда распределения: среднюю арифметическую, среднее квадратическое отклонение, коэффициент вариации.
4. Вычислить среднюю арифметическую по исходным данным (табл. 1), сравнить её с аналогичным показателем, рассчитанным для интервального ряда распределения. Объяснить причину их расхождения.
Сделать выводы по результатам выполнения Задания 1.
Выполнение Задания 1
Целью выполнения данного Задания является изучение состава и структуры выборочной совокупности предприятий путем построения и анализа статистического ряда распределения фирм по признаку Товарооборот.
1. Построение интервального ряда распределения предприятий по товарообороту
Для построения интервального ряда распределения определяем величину интервала h по формуле:
![]() ,
,
где ![]() –наибольшее и наименьшее значения признака в
исследуемой совокупности, k - число групп
интервального ряда.
–наибольшее и наименьшее значения признака в
исследуемой совокупности, k - число групп
интервального ряда.
При заданных k = 5, xmax = 795 тыс.руб. и xmin = 375тыс руб.
h = ![]() тыс.руб.
тыс.руб.
При h = 5 чел. границы интервалов ряда распределения имеют следующий вид (табл. 2):
Таблица 2
| Номер группы | Нижняя граница, тыс.руб. | Верхняя граница, тыс.руб |
| 1 | 375 | 459 |
| 2 | 459 | 543 |
| 3 | 543 | 627 |
| 4 | 627 | 711 |
| 5 | 711 | 795 |
Определяем число предприятий, входящих в каждую группу, используя принцип полуоткрытого интервала [ ), согласно которому предприятия со значениями признаков, которые служат одновременно верхними и нижними границами смежных интервалов (459, 543, 627, и 711 тыс.руб), будем относить ко второму из смежных интервалов.
Для определения числа предприятий в каждой группе строим разработочную таблицу 3 (данные графы 4 потребуются при выполнении Задания 2).
Таблица 3. Разработочная таблица для построения интервального ряда распределения и аналитической группировки
| Группы предприятий по товарообороту, тыс.руб. |
Номер предприятия |
Товарооборот, тыс.руб. |
Средние товарные запасы, Тыс. руб. |
|
1 |
2 |
3 |
4 |
| 375-459 | 11 | 375 | 150 |
| 19 | 384 | 158 | |
| 2 | 396 | 168 | |
| 12 | 429 | 2208 | |
| Всего | 4 | 1584 | 684 |
| 459-543 | 20 | 492 | 188 |
| 10 | 523 | 213 | |
| 25 | 528 | 215 | |
| 8 | 537 | 169 | |
| 5 | 540 | 210 | |
| Всего | 5 | 2620 | 995 |
| 543-627 | 4 | 543 | 221 |
| 23 | 550 | 191 | |
| 13 | 552 | 218 | |
| 7 | 576 | 214 | |
| 28 | 589 | 230 | |
| 22 | 591 | 239 | |
| 24 | 603 | 236 | |
| 21 | 610 | 237 | |
| 27 | 611 | 228 | |
| 1 | 614 | 256 | |
| 15 | 618 | 238 | |
| Всего | 11 | 6457 | 2508 |
| 627-711 | 29 | 627 | 263 |
| 14 | 642 | 227 | |
| 16 | 653 | 254 | |
| 3 | 681 | 252 | |
| 30 | 698 | 246 | |
| 17 | 704 | 251 | |
| 6 | 706 | 278 | |
| Всего | 7 | 4711 | 1771 |
| 711-795 | 9 | 744 | 288 |
| 18 | 759 | 293 | |
| 26 | 795 | 301 | |
| Всего | 3 | 2298 | 882 |
| Итого | 30 | 17670 | 6840 |
На основе групповых итоговых строк «Всего» табл. 3 формируем итоговую таблицу 4, представляющую интервальный ряд распределения предприятий по товарообороту.
Таблица 4. Распределение предприятий по товарообороту
|
Номер группы |
Группы предприятий по товарообороту, тыс.руб. x |
Число предприятий, fj |
| 1 | 375-459 | 4 |
| 2 | 459-543 | 5 |
| 3 | 543-627 | 11 |
| 4 | 627-711 | 7 |
| 5 | 711-795 | 3 |
| ИТОГО | 30 |
Приведем еще три характеристики полученного ряда распределения - частоты групп в относительном выражении, накопленные (кумулятивные) частоты Sj, получаемые путем последовательного суммирования частот всех предшествующих (j-1) интервалов, и накопленные частости, рассчитываемые по формуле
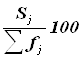 .
.
Таблица 5. Структура предприятий по товарообороту
|
Номер группы |
Группы предприятий по товарообороту, тыс.руб.x |
Число предприятий, f |
Накопленная частота Sj |
Накопленная частость, % | |
| в абсолютном выражении | в % к итогу | ||||
|
1 |
2 |
3 |
4 |
5 |
6 |
| 1 | 375-459 | 4 | 13,3 | 4 | 13,3 |
| 2 | 459-543 | 5 | 16,7 | 9 | 30,0 |
| 3 | 543-627 | 11 | 36,7 | 20 | 66,6 |
| 4 | 627-711 | 7 | 23,3 | 27 | 90,0 |
| 5 | 711-795 | 3 | 10 | 30 | 1000 |
| ИТОГО | 30 | 100 | |||
Вывод. Анализ интервального ряда распределения изучаемой совокупности предприятий показывает, что распределение предприятий по товарообороту не является равномерным: преобладают предприятия с товарооборотом от 543 тыс.руб. до 627 тыс.руб. (это 11 предприятий, доля которых составляет 36,7%); самые малочисленная группа предприятий имеет 711-795 тыс.руб.. Группа включает 3 предприятия, что составляет по 10% от общего числа фирм.
2. Нахождение моды и медианы полученного интервального ряда распределения графическим методом и путем расчетов
Для определения моды графическим методом строим по данным табл. 4 (графы 2 и 3) гистограмму распределения фирм по изучаемому признаку.
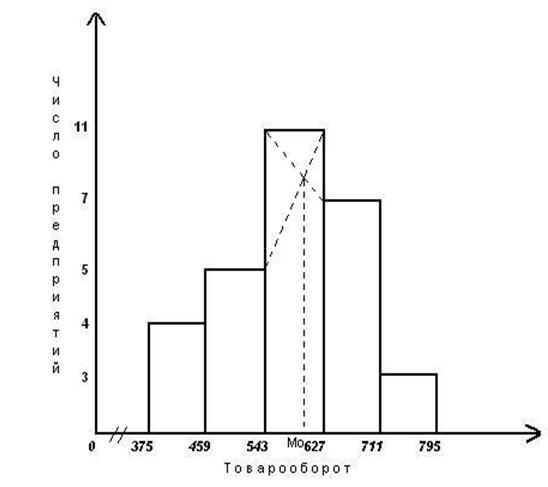
Рис. 1. Определение моды графическим методом
Расчет конкретного значения моды для интервального ряда распределения производится по формуле:

где хМo – нижняя граница модального интервала,
h – величина модального интервала,
fMo – частота модального интервала,
fMo-1 – частота интервала, предшествующего модальному,
fMo+1 – частота интервала, следующего за модальным.
Согласно табл. 4 модальным интервалом построенного ряда является интервал 35 - 40 чел., т.к. он имеет наибольшую частоту (f4=10). Расчет моды:
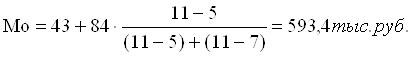
Вывод. Для рассматриваемой совокупности предприятий наиболее распространенный товарооборот характеризуется средней величиной 593,4 тыс. руб.
Для определения медианы графическим методом строим по данным табл. 5 кумуляту распределения предприятий по изучаемому признаку.
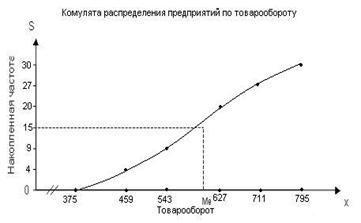
Рис. 2. Определение медианы графическим методом
Расчет конкретного значения медианы для интервального ряда распределения производится по формуле
 ,
,
где хМе– нижняя граница медианного интервала,
h – величина медианного интервала,
![]() – сумма всех
частот,
– сумма всех
частот,
fМе – частота медианного интервала,
SMе-1 – кумулятивная (накопленная) частота интервала, предшествующего медианному.
Определяем медианный
интервал. Медианным интервалом является интервал 543-627 тыс.руб., т.к. именно
в этом интервале накопленная частота Sj=20
впервые превышает полусумму всех частот (![]() ).
).
Расчет медианы:
![]()
Вывод. В рассматриваемой совокупности предприятий половина из них имеют товарооборот не более 588,3 тыс.руб., а другая половина – не менее 588,3 тыс.руб.
3. Расчет характеристик ряда распределения
Для расчета характеристик ряда распределения ![]() , σ, σ2,
Vσ на основе табл. 5 строим
вспомогательную таблицу 6 (
, σ, σ2,
Vσ на основе табл. 5 строим
вспомогательную таблицу 6 (![]() – середина интервала).
– середина интервала).
Таблица 6. Расчетная таблица для нахождения характеристик ряда распределения
| Группы предприятий по товарообороту, тыс.руб. |
Середина интервала,
|
Число предприятий, fj |
|
|
|
|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 375-459 | 417 | 4 | 1668 | -168 | 28224 | 112896 |
| 459-543 | 501 | 5 | 2505 | -84 | 7056 | 35280 |
| 543-627 | 585 | 11 | 6435 | 0 | 0 | 0 |
| 627-711 | 669 | 7 | 4683 | 84 | 7056 | 49392 |
| 711-795 | 753 | 3 | 2259 | 168 | 28224 | 84672 |
| ИТОГО | 30 | 17550 | 282240 |
Рассчитаем среднюю арифметическую взвешенную:
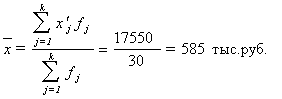
Рассчитаем среднее квадратическое отклонение:
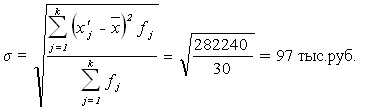
Рассчитаем дисперсию:
σ2 = 972 = 9409
Рассчитаем коэффициент вариации:
![]()
Вывод. Анализ полученных значений
показателей ![]() и
σ говорит о том, что средняя величина товарооборота
составляет 585 тыс.руб., отклонение от этой величины в ту или иную сторону
составляет в среднем 97 тыс. руб. (или 16,5%), наиболее характерный товарооборот
находится в пределах от 488 до 628 тыс. руб. (диапазон
и
σ говорит о том, что средняя величина товарооборота
составляет 585 тыс.руб., отклонение от этой величины в ту или иную сторону
составляет в среднем 97 тыс. руб. (или 16,5%), наиболее характерный товарооборот
находится в пределах от 488 до 628 тыс. руб. (диапазон ![]() ).
).
Значение Vσ = 16,5% не превышает 33%,
следовательно, вариация товарооборота в исследуемой совокупности предприятий
незначительна и совокупность по данному признаку однородна. Расхождение между
значениями ![]() ,
Мо и Ме незначительно (
,
Мо и Ме незначительно (![]() =585 тыс. руб., Мо=593,4
тыс. руб., Ме=588,3 чел.), что подтверждает вывод об однородности
совокупности фирм. Таким образом, найденное среднее значение среднесписочной
численности менеджеров (585тыс.руб.) является типичной, надежной
характеристикой исследуемой совокупности предприятий.
=585 тыс. руб., Мо=593,4
тыс. руб., Ме=588,3 чел.), что подтверждает вывод об однородности
совокупности фирм. Таким образом, найденное среднее значение среднесписочной
численности менеджеров (585тыс.руб.) является типичной, надежной
характеристикой исследуемой совокупности предприятий.
4. Вычисление средней арифметической по исходным данным о среднесписочной численности менеджеров фирм
Для расчета применяется формула средней арифметической простой:
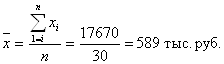 ,
,
Причина расхождения
средних величин, рассчитанных по исходным данным (17550 тыс. руб.) и по
интервальному ряду распределения (17670 тыс. руб.), заключается в том, что в
первом случае средняя определяется по фактическим значениям исследуемого
признака для всех 30-ти фирм, а во втором случае в качестве значений признака
берутся середины интервалов ![]() и, следовательно, значение средней будет менее точным.
Вместе с тем, при округлении обеих рассматриваемых величин их значения
совпадают, что говорит о достаточно равномерном распределении товарооборота
внутри каждой группы интервального ряда.
и, следовательно, значение средней будет менее точным.
Вместе с тем, при округлении обеих рассматриваемых величин их значения
совпадают, что говорит о достаточно равномерном распределении товарооборота
внутри каждой группы интервального ряда.
Задание 2
По исходным данным (табл. 1) с использованием результатов выполнения Задания 1 необходимо выполнить следующее:
1. Установить наличие и характер корреляционной связи между признаками товарооборот и средние товарные запасы, образовав шесть групп с равными интервалами по каждому из признаков, используя методы:
а) аналитической группировки;
б) корреляционной таблицы.
2. Измерить тесноту корреляционной связи, используя коэффициент детерминации и эмпирическое корреляционное отношение.
Сделать выводы по результатам выполнения задания 2.
Выполнение задания 2
Целью выполнения данного задания является выявление наличия корреляционной связи между факторным и результативным признаками, а также установление направления связи и оценка ее тесноты.
По условию Задания 2 факторным является признак товарооборот, результативным – признак средние товарные запасы.
1. Установление наличия и характера корреляционной связи между признаками товарооборотом и средними товарными запасами методами аналитической группировки и корреляционных таблиц
1а. Применение метода аналитической группировки
Аналитическая группировка
строится по факторному признаку Х и для каждой j-ой
группы ряда определяется среднегрупповое значение ![]() результативного
признака Y. Если с ростом значений фактора Х
от группы к группе средние значения
результативного
признака Y. Если с ростом значений фактора Х
от группы к группе средние значения ![]() систематически
возрастают (или убывают), между признаками X и Y имеет место корреляционная связь.
систематически
возрастают (или убывают), между признаками X и Y имеет место корреляционная связь.
Используя разработочную таблицу 3, строим аналитическую группировку, характеризующую зависимость между факторным признаком Х- товарооборот и результативным признаком Y – средние товарные запасы. Макет аналитической таблицы имеет следующий вид (табл. 7):
Таблица 7. Зависимость объема продаж от среднесписочной численности менеджеров
| Номер группы |
Группы предприятий по товарообороту, тыс. руб. x |
Число предприятий, fj |
Средние товарные запасы, тыс. руб. | |
| всего |
в среднем на одно предприятие,
|
|||
|
1 |
2 |
3 |
4 |
5=4:3 |
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
|
ИТОГО |
||||
Групповые средние значения ![]() получаем
из таблицы 3, основываясь на итоговых строках «Всего». Построенную
аналитическую группировку представляет табл. 8:
получаем
из таблицы 3, основываясь на итоговых строках «Всего». Построенную
аналитическую группировку представляет табл. 8:
Таблица 8. Зависимость объема продаж от среднесписочной численности менеджеров
| Номер группы |
Группы предприятий по товарообороту, тыс. руб. x |
Число предприятий, fj |
Средние товарные запасы, тыс. руб. | |
| всего |
в среднем на одно предприятие,
|
|||
|
1 |
2 |
3 |
4 |
5=4:3 |
| 1 | 375-459 | 4 | 684 | 171 |
| 2 | 459-543 | 5 | 995 | 199 |
| 3 | 543-627 | 11 | 1508 | 228 |
| 4 | 627-711 | 7 | 1771 | 253 |
|
1 |
2 |
3 |
4 |
5 |
| 5 | 711-795 | 3 | 882 | 294 |
| ИТОГО | 30 |
6840 |
1145 |
|
Вывод. Анализ данных табл. 8 показывает, что с увеличением товарооборота от группы к группе систематически возрастает и средний товарный запас по каждой группе предприятий, что свидетельствует о наличии прямой корреляционной связи между исследуемыми признаками.
1б. Применение метода корреляционных таблиц
Корреляционная таблица строится как комбинация двух рядов распределения по факторному признаку Х и результативному признаку Y. На пересечении j-ой строки и k-ой графы таблицы указывается число единиц совокупности, входящих в j-ый интервал по признаку X и в k-ый интервал по признаку Y. Концентрация частот около диагонали построенной таблицы свидетельствует о наличии корреляционной связи между признаками - прямой или обратной. Связь прямая, если частоты располагаются по диагонали, идущей от левого верхнего угла к правому нижнему, обратная - по диагонали от правого верхнего угла к левому нижнему.
Для построения корреляционной таблицы необходимо знать величины и границы интервалов по двум признакам X и Y. Для факторного признака Х – Товарооборот эти величины известны из табл. 4 Определяем величину интервала для результативного признака Y – средние товарные запасы при k = 5, уmax = 301 тыс. руб., уmin = 150 тыс. руб.:
![]()
Границы интервалов ряда распределения результативного признака Y имеют вид:
Таблица 9
| Номер группы | Нижняя граница, Тыс. руб. | Верхняя граница, Тыс. руб. |
| 1 | 150 | 180,2 |
| 2 | 180,2 | 210,4 |
| 3 | 210,4 | 240,6 |
| 4 | 240,6 | 270,8 |
| 5 | 270,8 | 301 |
Подсчитывая для каждой группы число входящих в нее фирм с использованием принципа полуоткрытого интервала [ ), получаем интервальный ряд распределения результативного признака (табл. 10).
Таблица 10. Интервальный ряд распределения фирм по объёму продаж
|
Группы предприятий по среднему товарному запасу, тыс. руб. у |
Число предприятий, fj |
| 150-180,2 | 4 |
| 180,2-210,4 | 4 |
| 210,4-240,6 | 12 |
| 240,6-270,8 | 6 |
| 270,8-301 | 4 |
| ИТОГО | 30 |
Используя группировки по факторному и результативному признакам, строим корреляционную таблицу (табл. 11).
Таблица 11. Корреляционная таблица зависимости объема продаж от среднесписочной численности менеджеров
| Группы предприятий по товарообороту, тыс. руб. | Группы предприятий по среднему товарному запасу, тыс. руб. | ИТОГО | ||||
| 150-180,2 | 180,2-210,4 | 210,4-240,6 | 240,6-270,8 | 270,8-301 | ||
| 375-459 | 2 | 1 | 3 | |||
| 459-543 | 1 | 2 | 2 | 5 | ||
| 543-627 | 1 | 1 | 9 | 1 | 12 | |
| 627-711 | 1 | 5 | 1 | 7 | ||
| 711-795 | 3 | 3 | ||||
| ИТОГО | 4 | 4 | 12 | 6 | 4 | 30 |
Вывод. Анализ данных табл. 11 показывает, что распределение частот групп произошло вдоль диагонали, идущей из левого верхнего угла в правый нижний угол таблицы. Это свидетельствует о наличии прямой корреляционной связи между среднесписочной численностью менеджеров и объемом продаж фирмами.
2.
Измерение тесноты корреляционной связи с использованием коэффициента
детерминации ![]() и эмпирического корреляционного
отношения
и эмпирического корреляционного
отношения ![]()
Коэффициент
детерминации ![]() характеризует силу влияния факторного
(группировочного) признака Х на результативный признак Y и рассчитывается как доля
межгрупповой дисперсии
характеризует силу влияния факторного
(группировочного) признака Х на результативный признак Y и рассчитывается как доля
межгрупповой дисперсии ![]() признака Y в его общей дисперсии
признака Y в его общей дисперсии![]() :
:
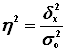
где ![]() – общая
дисперсия признака Y,
– общая
дисперсия признака Y,
![]() – межгрупповая
(факторная) дисперсия признака Y.
– межгрупповая
(факторная) дисперсия признака Y.
Общая
дисперсия ![]() характеризует вариацию результативного признака, сложившуюся под влиянием
всех действующих на Y факторов (систематических и
случайных) и вычисляется по формуле
характеризует вариацию результативного признака, сложившуюся под влиянием
всех действующих на Y факторов (систематических и
случайных) и вычисляется по формуле
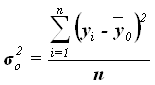 ,
,
где yi – индивидуальные значения результативного признака;
![]() – общая средняя значений
результативного признака;
– общая средняя значений
результативного признака;
n – число единиц совокупности.
Межгрупповая
дисперсия ![]() измеряет систематическую вариацию результативного признака,
обусловленную влиянием признака-фактора Х (по которому
произведена группировка) и вычисляется по формуле
измеряет систематическую вариацию результативного признака,
обусловленную влиянием признака-фактора Х (по которому
произведена группировка) и вычисляется по формуле
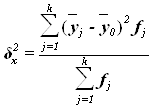 ,
,
где ![]() –групповые средние,
–групповые средние,
![]() – общая средняя,
– общая средняя,
![]() –число единиц в
j-ой группе,
–число единиц в
j-ой группе,
k – число групп.
Для расчета показателей ![]() и
и ![]() необходимо знать величину общей средней
необходимо знать величину общей средней ![]() , которая вычисляется как средняя арифметическая
простая по всем единицам совокупности:
, которая вычисляется как средняя арифметическая
простая по всем единицам совокупности:
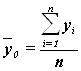
Значения числителя и
знаменателя формулы имеются в табл. 8. Используя эти данные, получаем общую
среднюю ![]() :
:
![]() =
= ![]() =228 тыс. руб.
=228 тыс. руб.
Для расчета общей
дисперсии ![]() применяется вспомогательная таблица 12.
применяется вспомогательная таблица 12.
Таблица 12. Вспомогательная таблица для расчета общей дисперсии
|
Номер предприятия |
Средние товарные запасы, тыс.руб. |
|
|
|
1 |
2 |
3 |
4 |
| 1 | 256 | 28 | 784 |
| 2 | 168 | -60 | 3600 |
| 3 | 252 | 24 | 576 |
| 4 | 221 | 7 | 49 |
| 5 | 210 | -18 | 324 |
| 6 | 278 | 50 | 2500 |
| 7 | 214 | -14 | 196 |
| 8 | 169 | -59 | 3481 |
| 9 | 288 | 60 | 3600 |
| 10 | 213 | -15 | 225 |
| 11 | 150 | -78 | 6084 |
| 12 | 208 | -20 | 400 |
| 13 | 218 | -10 | 100 |
| 14 | 227 | -1 | 1 |
| 15 | 238 | 10 | 100 |
| 16 | 254 | 26 | 676 |
| 17 | 251 | 23 | 529 |
| 18 | 293 | 65 | 4225 |
| 19 | 158 | -70 | 4900 |
| 20 | 188 | -40 | 1600 |
| 21 | 237 | 9 | 81 |
| 22 | 239 | 11 | 121 |
| 23 | 191 | -37 | 1369 |
| 24 | 236 | 2 | 64 |
| 25 | 215 | -13 | 169 |
| 26 | 301 | 73 | 5329 |
| 27 | 228 | 0 | 0 |
| 28 | 230 | 2 | 4 |
| 29 | 263 | 35 | 1225 |
| 30 | 246 | 18 | 324 |
| Итого | 6840 | 14 | 42636 |
Рассчитаем общую дисперсию:
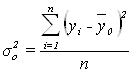 =
=![]()
Для расчета межгрупповой
дисперсии ![]() строится вспомогательная таблица 13,
При этом используются групповые средние значения
строится вспомогательная таблица 13,
При этом используются групповые средние значения ![]() из табл.
из табл.
Таблица 13ю Вспомогательная таблица для расчета межгрупповой дисперсии
|
Группы предприятий по товарообороту, тыс. руб. x |
Число предприятий, fj |
Среднее значение в группе, тыс. руб. |
|
|
|
1 |
2 |
3 |
4 |
5 |
| 375-459 | 4 | 171 | -57 | 12996 |
| 459-543 | 5 | 199 | -29 | 4205 |
| 543-627 | 11 | 228 | 0 | 0 |
| 627-711 | 7 | 253 | 25 | 4375 |
|
1 |
2 |
3 |
4 |
5 |
| 711-795 | 3 | 294 | 66 | 13068 |
| ИТОГО | 30 | 34644 |
Рассчитаем межгрупповую дисперсию:
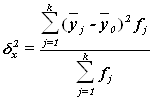
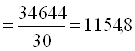
Определяем коэффициент детерминации:
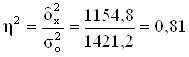 или 81%
или 81%
Вывод. 81% вариации объёма продаж товаров фирмами обусловлено вариацией среднесписочной численности менеджеров по продажам, а 19% – влиянием прочих неучтенных факторов.
Эмпирическое
корреляционное отношение ![]() оценивает тесноту связи
между факторным и результативным признаками и вычисляется по формуле
оценивает тесноту связи
между факторным и результативным признаками и вычисляется по формуле
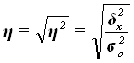
Рассчитаем показатель ![]() :
:
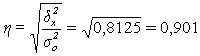 = 90,1%
= 90,1%
Вывод: согласно шкале Чэддока связь между товарооборотом и средними товарными запасами предприятий является весьма тесной.
Задание 3
По результатам выполнения Задания 1 с вероятностью 0,954 необходимо определить:
1) ошибку выборки для средней величины товарооборота торгового предприятия, а также границы, в которых будет находиться генеральная средняя.
2) ошибку выборки доли торговых предприятий с объемом товарооборота 627 и более тыс. руб., а также границы, в которых будет находиться генеральная доля фирм.
Выполнение Задания 3
Целью выполнения данного Задания является определение для генеральной совокупности предприятий района границ, в которых будут находиться средняя величина товарооборота, и доля предприятий с товарооборотом не менее 627 тыс. руб.
1. Определение ошибки выборки для величины товарооборота, а также границ, в которых будет находиться генеральная средняя
Применяя выборочный метод наблюдения, необходимо рассчитать ошибки выборки (ошибки репрезентативности), т.к. генеральные и выборочные харак- теристики, как правило, не совпадают, а отклоняются на некоторую величину ε.
Принято вычислять два
вида ошибок выборки - среднюю ![]() и предельную
и предельную ![]() .
.
Для расчета средней
ошибки выборки ![]() применяются различные формулы
в зависимости от вида и способа отбора единиц из генеральной
совокупности в выборочную.
применяются различные формулы
в зависимости от вида и способа отбора единиц из генеральной
совокупности в выборочную.
Для собственно-случайной
и механической выборки с бесповторным способом отбора
средняя ошибка ![]() для выборочной средней
для выборочной средней ![]() определяется
по формуле
определяется
по формуле
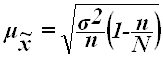 ,
,
где ![]() – общая
дисперсия изучаемого признака,
– общая
дисперсия изучаемого признака,
N – число единиц в генеральной совокупности,
n – число единиц в выборочной совокупности.
Предельная ошибка выборки
![]() определяет границы, в пределах которых будет находиться генеральная
средняя:
определяет границы, в пределах которых будет находиться генеральная
средняя:
![]() ,
,
![]() ,
,
где ![]() – выборочная средняя,
– выборочная средняя,
![]() – генеральная средняя.
– генеральная средняя.
Предельная ошибка выборки
![]() кратна средней ошибке
кратна средней ошибке ![]() с коэффициентом кратности t (называемым также коэффициентом доверия):
с коэффициентом кратности t (называемым также коэффициентом доверия):
![]()
Коэффициент кратности t зависит от значения доверительной
вероятности Р, гарантирующей вхождение генеральной средней в
интервал ![]() , называемый доверительным
интервалом.
, называемый доверительным
интервалом.
Наиболее часто используемые доверительные вероятности Р и соответствующие им значения t задаются следующим образом (табл. 14):
Таблица 14
|
Доверительная вероятность P |
0,683 | 0,866 | 0,954 | 0,988 | 0,997 | 0,999 |
|
Значение t |
1,0 | 1,5 | 2,0 | 2,5 | 3,0 | 3,5 |
По условию Задания 2
выборочная совокупность насчитывает 30 фирм, выборка 20% механическая,
следовательно, генеральная совокупность включает 150 фирм.
Выборочная средняя ![]() , дисперсия
, дисперсия ![]() определены в Задании 1. Значения параметров,
необходимых для решения задачи, представлены в табл. 15:
определены в Задании 1. Значения параметров,
необходимых для решения задачи, представлены в табл. 15:
Таблица 15
Р |
t | n | N |
|
|
| 0,954 | 2 | 30 | 150 | 585 | 9409 |
Рассчитаем среднюю ошибку выборки:
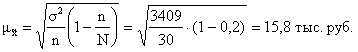
Рассчитаем предельную ошибку выборки:
![]() тыс. руб.
тыс. руб.
Определим доверительный интервал для генеральной средней:
![]()
![]() тыс. руб.
тыс. руб.
Вывод. На основании проведенного выборочного обследования с вероятностью 0,954 можно утверждать, что для генеральной совокупности предприятий средняя величина товарооборота находится в пределах от 553 до 616 тыс. руб.
2. Определение ошибки выборки для доли фирм товарооборотом 627 тыс. руб. и более, а также границ, в которых будет находиться генеральная доля
Доля единиц выборочной совокупности, обладающих тем или иным заданным свойством, выражается формулой
![]() ,
,
где m – число единиц совокупности, обладающих заданным свойством;
n – общее число единиц в совокупности.
Для собственно-случайной
и механической выборки с бесповторным способом отбора
предельная ошибка
выборки ![]() доли
единиц, обладающих заданным свойством, рассчитывается по формуле
доли
единиц, обладающих заданным свойством, рассчитывается по формуле
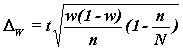 ,
,
где w – доля единиц совокупности, обладающих заданным свойством;
(1-w) – доля единиц совокупности, не обладающих заданным свойством,
N – число единиц в генеральной совокупности,
n– число единиц в выборочной совокупности.
Предельная ошибка выборки
![]() определяет границы, в пределах
которых будет находиться генеральная доля р единиц, обладающих
исследуемым признаком:
определяет границы, в пределах
которых будет находиться генеральная доля р единиц, обладающих
исследуемым признаком:
![]()
По условию Задания 3 исследуемым свойством фирм является равенство или превышение товарооборота величины 627 тыс. руб.
Число предприятий с данным свойством определяется из табл. 3: m=7
Рассчитаем выборочную долю:
![]()
Рассчитаем предельную ошибку выборки для доли:
![]()
Определим доверительный интервал генеральной доли:
![]()
0,181 ![]() 0,485
0,485
18,1% ![]() 48,5%
48,5%
Вывод. С вероятностью 0,954 можно утверждать, что в генеральной совокупности предприятий района доля предприятий с товарооборотом 627 тыс. руб. и более будет находиться в пределах от 18% до 48,5%.
Задание 4
Имеются данные о продаже товара А на трех городских рынках:
Таблица 16
| Рынки | Базисный период | Отчетный период | ||
|
Средняя цена за 1 кг., руб. (р0) |
Продано, т (q0) |
Изменение цены, % (p1) |
Индекс физического объема(q1) |
|
| 1 | 180 | 350 | 10 | 1,2 |
| 2 | 200 | 280 | Без изменений | 0,9 |
| 3 | 220 | 70 | -5 | 1,1 |
Определите:
1. Индексы цен переменного, постоянного состава и структурных сдвигов.
2. Абсолютное изменение средней цены товара в результате влияния отдельных факторов.
Таблица 17
| Рынки | Базисный период | Отчетный период | Расчетные графы | ||||
|
Средняя цена за 1 кг., руб. (р0) |
Продано, т (q0) |
Изменение цены, % (p1) |
Индекс физического объема (q1) |
p0q0 |
p1q1 |
p0q1 |
|
| 1 | 180 | 350 | 198 | 1,2 | 63000 | 70131,6 | 63756 |
| 2 | 200 | 280 | 200 | 0,9 | 56000 | 56504 | 56500 |
| 3 | 220 | 70 | 209 | 1,1 | 15400 | 14776,3 | 15554 |
| Итого | - | 700 | - | 134400 | 141407,9 | 135810 | |
Вычислим индекс цен переменного состава:
Ipпс=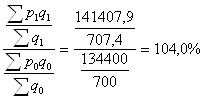
Из таблицы видно, что цена продукции на каждом рынке в отчетном периоде по сравнению с базисным изменилась. В целом же средняя цена выросла на 4 % .Это объясняется влиянием изменений структуры реализации продукции по торговым городским рынкам. В базисном периоде по более низкой цене продавали продукцию меньше, чем в отчетном периоде по более высокой цене.
Рассчитываем индекс структурных сдвигов:
Ipccт=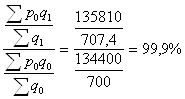
Первая часть приведенной
формулы 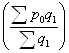 позволяет
ответить на вопрос, какой была бы средняя цена в отчетном периоде. Вторая часть
формулы
позволяет
ответить на вопрос, какой была бы средняя цена в отчетном периоде. Вторая часть
формулы 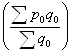 отражает
фактическую среднюю цену базисного периода.
отражает
фактическую среднюю цену базисного периода.
Рассчитанный индекс показал, что за счет структурных сдвигов цены значительно не изменились.
Определим индекс фиксированного или постоянного состава, который не учитывает изменения структуры продаж:
Ipфс = 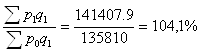
Индекс цен фиксированного состава равен 104,1%, что позволяет сделать следующий вывод: если бы структура продаж продукции на городских рынках не изменилась, средняя цена возросла бы на 4,1%., что и произойдет в дальнейшем.
Между данными индексами существует следующая взаимосвязь:
Ipфс * Iccт = Ipпс ;
1,041 * 0,99 =1,040
Определим абсолютное изменение средней цены товара в результате влияния отдельных факторов:
D pq = åp1q1 - å p0q0
D pq = 141407,9 – 134400 =7008 руб.
Заключение
Статистические ряды распределения являются базисным методом для любого статистического анализа.
Статистический ряд распределения представляет собой упорядоченное распределение единиц изучаемой совокупности на группы по определенному варьирующему признаку, характеризует структуру изучаемого явления. Анализируя рассчитанные показатели статистического ряда распределения, можно делать выводы об однородности или неоднородности совокупности, закономерности распределения и границах варьирования единиц совокупности. Изучив основные приемы исследования и практики применения рядов распределения, а также методику вычисления наиболее важных статистических величин, необходимо отметить, что конечная цель изучения статистики в целом - анализ изучаемого явления - крайне важен для всех сфер человеческой жизни. Анализ отображает явления в целом и вместе с этим учитывает влияние каждого фактора в отдельности. На основании проведенного анализа можно учитывать и прогнозировать факторы, негативно влияющие на развитие событий.
Социально-экономическая статистика обеспечивает предоставление важной цифровой информации об уровне и возможностях развития страны: ее экономическом положении, уровне жизни населения, его составе и численности, рентабельности предприятий, динамике безработице и т.д. Статистическая информация является одним из решающих ориентиров государственной экономической политики.
Статистические методы используют комплексно. Выделяют три основные стадии экономико-статистического исследования: сбор первичной статистической информации, статистическая сводка и обработка первичной информации, обобщение и интепретация статистической информации.
Качество, достоверность статистической информации определяют эффективность использования статистики на любом уровне и в любой сфере.
Литература
1. Статистика: Учеб. пособие/А.В. Багат, М.М. Конкина, В.М. Симчера и др.; Под ред. В.М. Симчеры.- М.: Финансы и статистика, 2005.
2. Громыко Г.Л. Теория статистики: Учебник. - М.: ИНФРА-М, 2006.
3. Практикум по статистике: Учеб. пособие для вузов/ Под ред. В.М. Симчеры. - М.: Финстатинформ, 1999.
4. Гусаров В.М. Статистика: Учеб. пособие для вузов. - М.: ЮНИТИ - ДАНА, 2001.
5. Гусаров В.М. Статистика: Учеб пособие/ В.М. Гусаров, Е.И. Кузнецова. – 2-е изд., перераб. и доп. – М.: ЮНИТИ-ДАНА, 2007.
6. Общая теория статистики: Статистическая методология в изучении коммерческой деятельности: Учебник / Под. ред. Башиной О.Э., Спирина А.А. – М.: Финансы и статисика, 2005.
7. Практикум по теории статистики: Учебное пособие/Под. ред. Шмойловой Р.А. – М.: Финансы и статистика, 2004.
8. Теория статистики: Учебник/Под. ред. Шмойловой Р.А. – М.: Финансы и статистика, 2001; 2003; 2006.
9. http://www.gks.ru